
基本信息
- 论文:Lumos: Increasing Awareness of Analytic Behavior during Visual Data Analysis
- 作者:Arpit Narechania, Adam Coscia, Emily Wall, Alex Endert
- 来源:VIS 2021
- 链接:https://arxiv.org/abs/2108.02909
- 视频:https://www.youtube.com/watch?v=o2lGQLaT7T4
一作、二作、四作来自于乔治亚理工,三作来自埃默里大学,
| Arpit Narechania | Adam Coscia | Emily Wall | Alex Endert |
|---|---|---|---|
 |
 |
 |
 |
| Ph. D. from~2019 | Ph. D. from~2020 | Assistant Prof. | Associate Prof. |
| 人机交互、可视界面、自动驾驶、自然语言、cognitive bias | 人机交互、可视分析、cognitive bias | decision making、可视分析、cognitive bias | 人机交互、信息可视化、可视分析 |
Introduction - 问题 & 贡献
浏览数据时,可能会产生无意间的偏差从而引起偏见,当你浏览的数据分布和真实的数据分布存在区别时,你就会形成偏见,比如你见过的黑人都犯罪,你会觉得黑人都犯罪,然而现有的分析工具(Tableau/Excel)并不会报告上述偏差。
作者想要提出能够在分析过程中反馈偏差的工具,于是他们贡献了 Lumos,一个可视化数据交互历史的分析工具,能够在数据分析和决策时提醒用户存在潜在的交互偏见。
Related Work - 相关工作
作者主要展示了两个方面的相关工作,Graphical History 相关的工作主要聚焦于展示交互的历史,本文的工作受到它们的启发;Modeling User Behavior 的工具主要提出一些能够描绘行为的指标,本文的 metrics 来源 17 年 VAST,衡量用户交互行为和均匀行为 (uniform behavior)的偏差。以往的交互焦聚于 explicit subset selection; 本文更广(包括点击、悬浮、可视化配置、过滤器配置等)。
Terminologies - 术语
- Interaction Logs:交互日志,记录了用户交互行为(如 hover)以及用户界面元素(如 散点图的 datapoints)
- Analytic Behavior Model:分析行为模型,根据交互日志量化用户行为的模型(比如计算被交互的 datapoints 及其属性的分布)
- Interaction Traces:交互痕迹,交互行为在界面上的视觉反馈,通过从两方面增加视觉痕迹(visual scents):in-situ 和 ex-situ
- Awareness:意识,知道在探索过程中发生了什么,从而可以进行推理
Design Goals - 设计目标
作者们根据:1)相似的可视分析工具;2)试点实验的反馈;3)他们自己关于 usability 的假设,总结并得到了如下的射击目标:
DG1. 捕获并展示分析行为中的相关属性
DG2. 捕获并展示分析行为中的相关数据点
DG3.帮助设置不同的目标基准分布
DG4.帮助分析行为和基准分布的比较
DG5.在可视数据探索时展示awareness
量化分析行为 - Quantifying Analytic Behavior
作者采用了两个方面来量化分析行为:
- 第一个为属性分布指标 (Wall et al.’s attribute distribution metric, AD metric),泳衣描述用户交互行为和期望行为之间的偏差,0 表示无偏见,1 表示高偏见。
- 第二个为数据/属性的交互频率,主要记录对不同数据点和属性的交互次数
用户界面 - User Interface
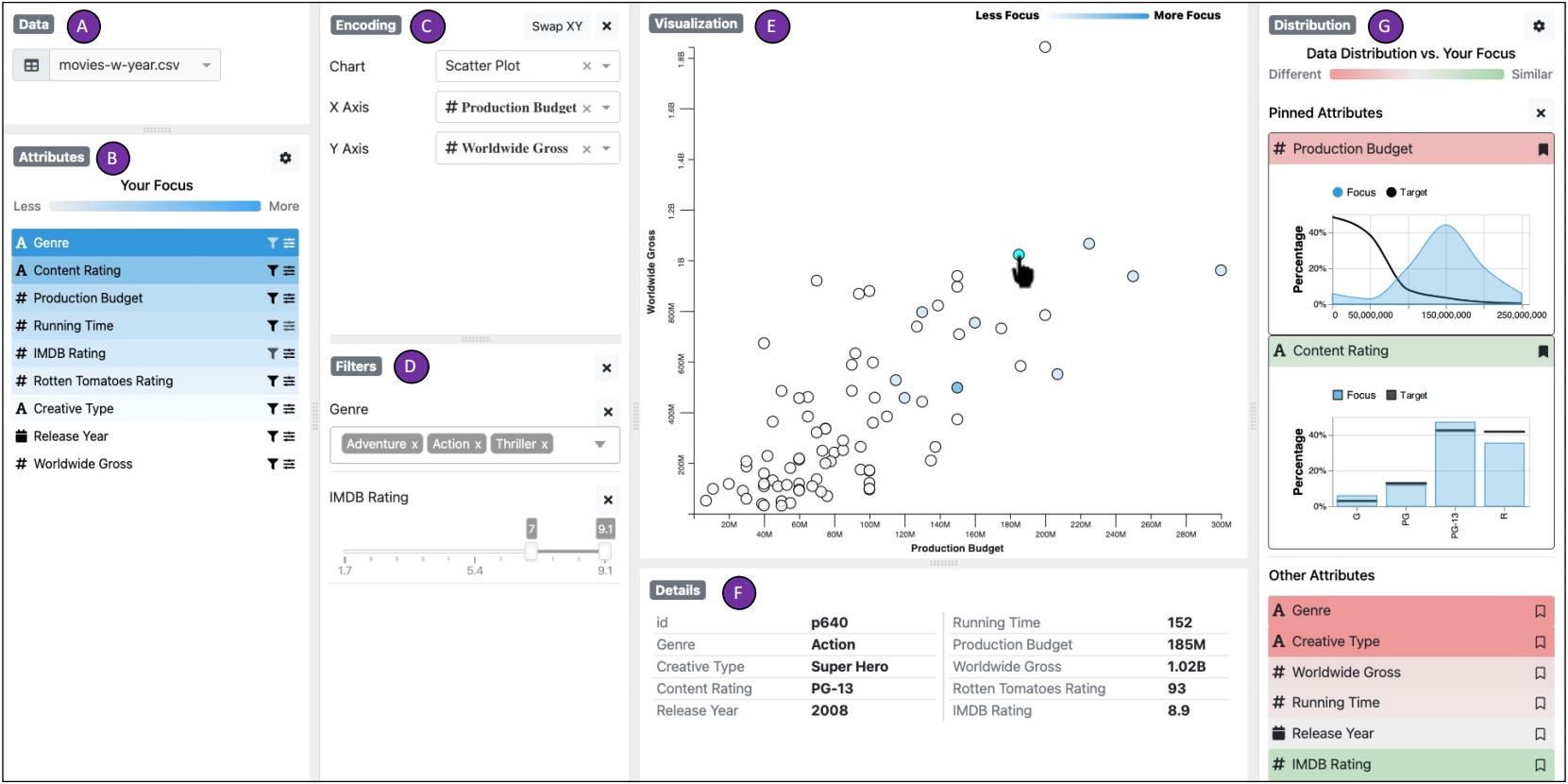
内置/外置的交互踪迹
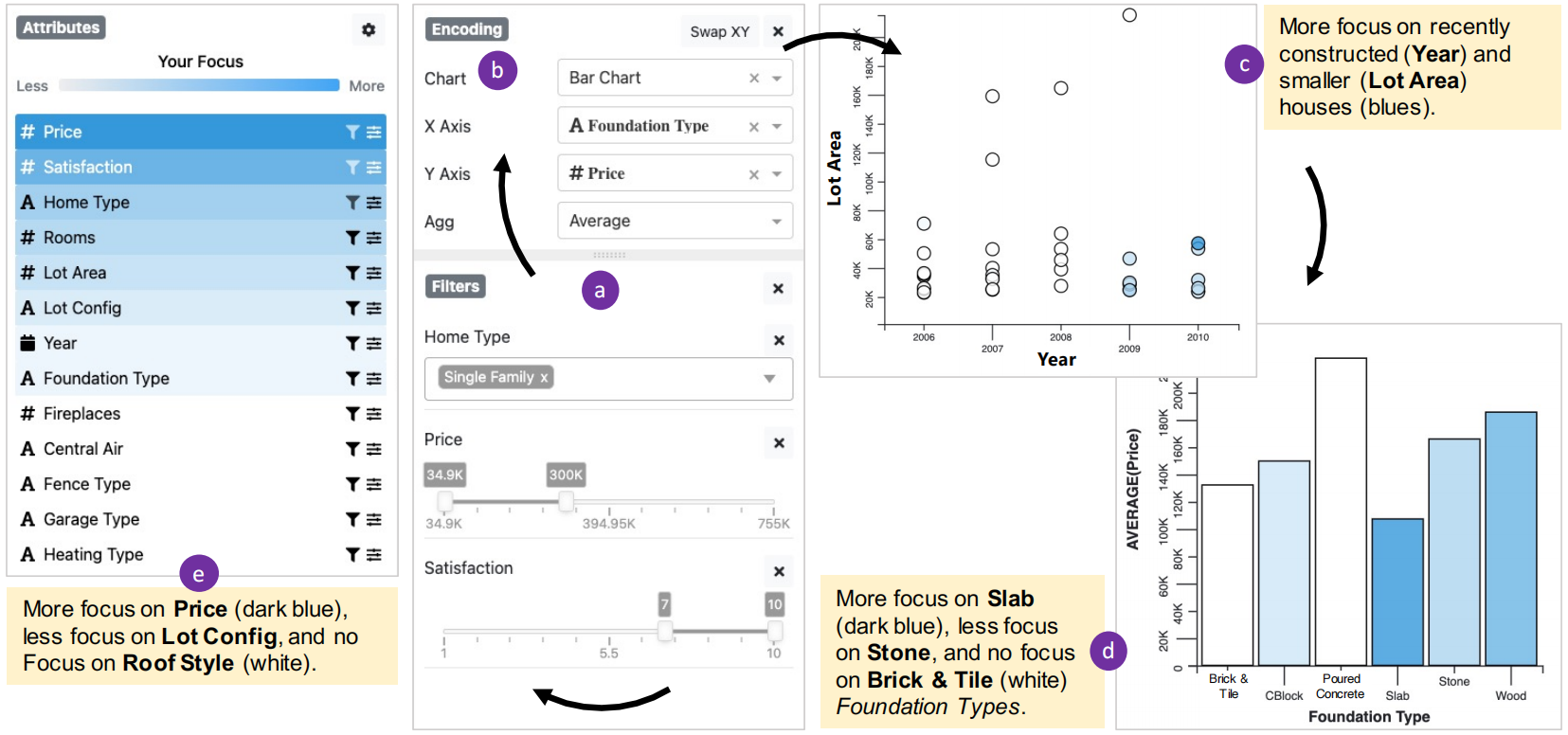
作者提出了两种展示 interaction traces(交互踪迹)的方法,in-situ 的方法将 Interaction Traces集成在数据点/属性上,如下图所示,颜色展示交互频率。
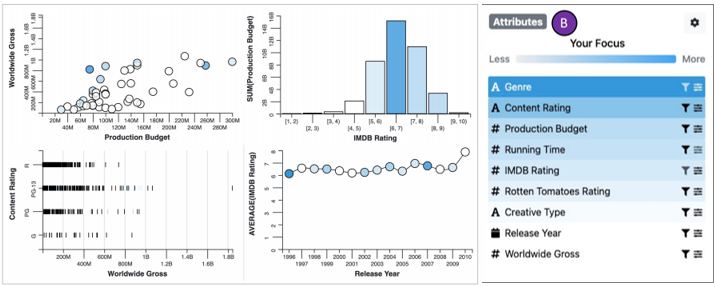
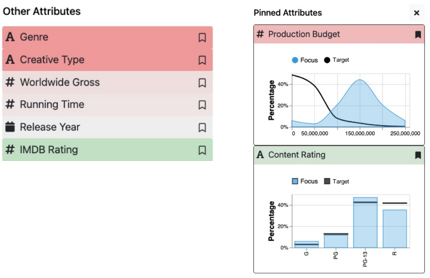
ex-situ 的方法通过另外的视图来展示,下图左用颜色编码了不同属性上的浏览与目标之间的相似度,下图右则直接描绘了浏览的数据分布(蓝色区域)和目标分布(黑线)之间的区别。
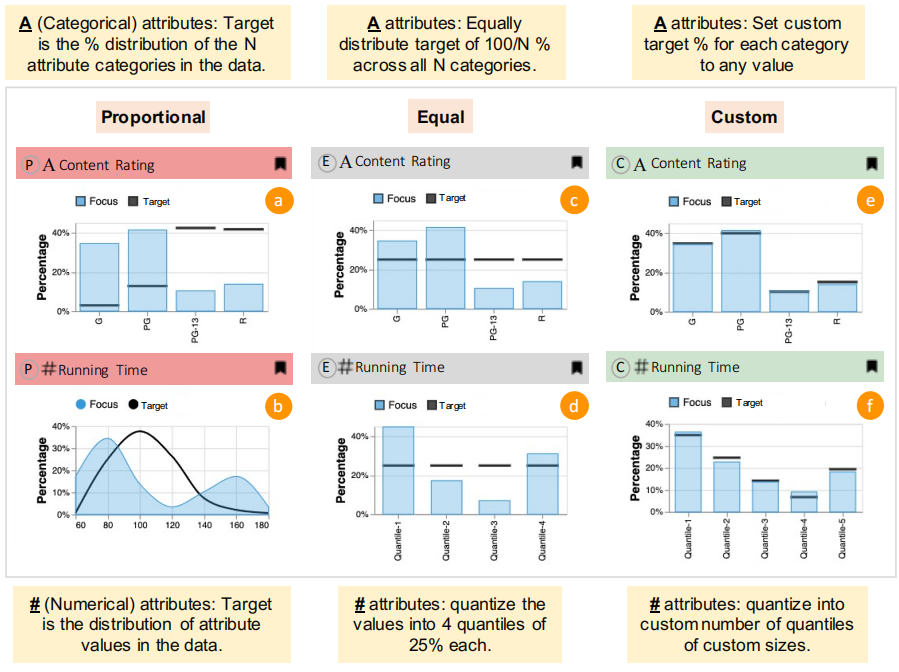
配置不同的目标分布
作者提供了两种不同的预制的分布:propositional(下图左)的分布表示目标分布应该和源数据分布保持一致(成比例的),equal(下图中)的分布则表示用户的浏览应该雨露均沾,不同的范围都应该浏览同样多;custom(下图右)则允许用户自己通过拖动,sketch 一个自定义的分布。
使用场景
两个使用场景,不在赘述,第一个展示了系统能够增加对于交互行为的意识(increasing awareness of analytic behavior),第二个则展示系统能够消除分析行为的偏见(Mitigating biased analytic behavior)
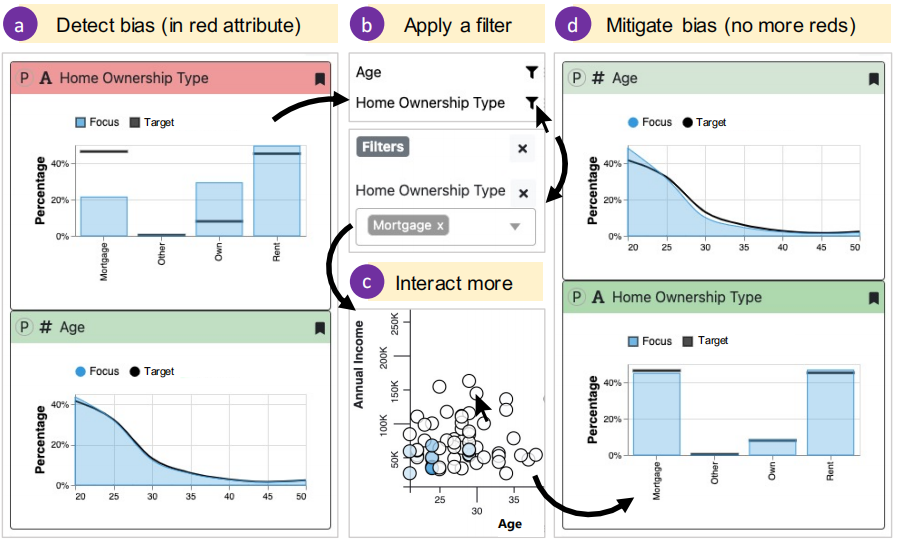
评估
作者采用了一个 between-subjects qualitative study,将 24 个人分成实验组和对照组,实验组使用拥有 awareness 的系统,对照组使用没有 awareness 的系统,看不到任何的 interaction traces。
- 任务:分析电影数据集的分析,推荐电影出品公司下次应该出品的电影的特征(“analyze a dataset of moviesto recommend the characteristics of movies that a movie production company should make next”)
- 假设
- H1. interaction traces 能够唤起对分析行为的意识
- H2. 两组之间的交互行为会有区别
- H3. ex-situ 的 awareness 会比 in-situ 的 awareness 更有用
- H4. 实验组的参与者会对 interaction traces 有反应,减少偏差
首先,作者让被试们对不同模块的 usefulness 进行打分,分别比较了对照组和实验组的打分区别(下图 A),以及在实验组中,in-situ 的交互痕迹与 ex-situ 的交互痕迹之间的打分区别(下图 B),结合打分结果与被试的访谈,作者讨论了很多相关内容,证明了 H3。
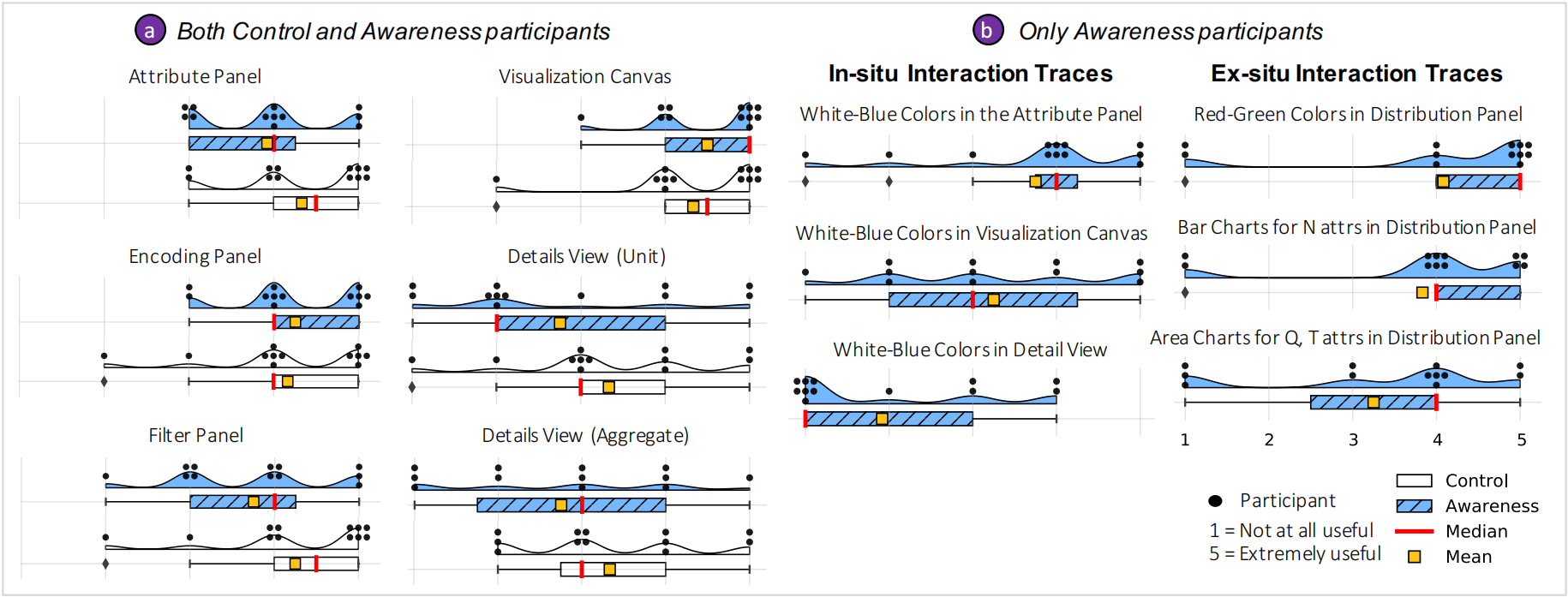
紧接着,作者还让被试谈及自己的 awareness moments,也就是他们意识到自己有 bias 的时刻,以此来验证 H1 和 H4。
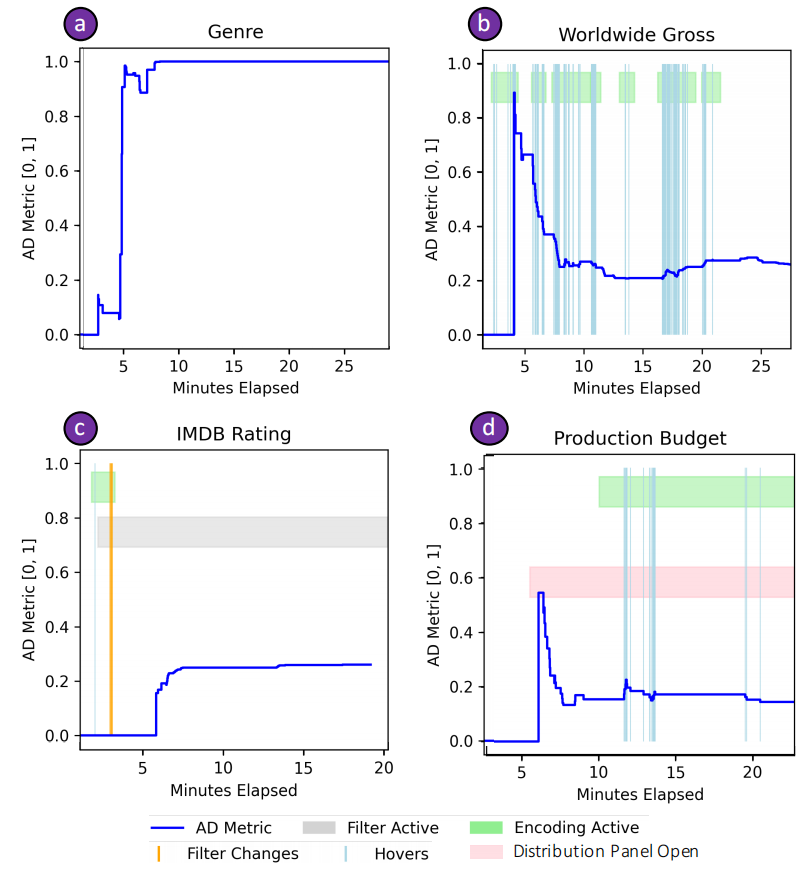
作者还记录并统计了不同的交互次数,展现了对照组和实验组的交互行为的区别,主要包括对数据点的交互,对属性的交互,图表类型选择、过滤和编码,以及 distribution panel 中的不同 card 的使用。
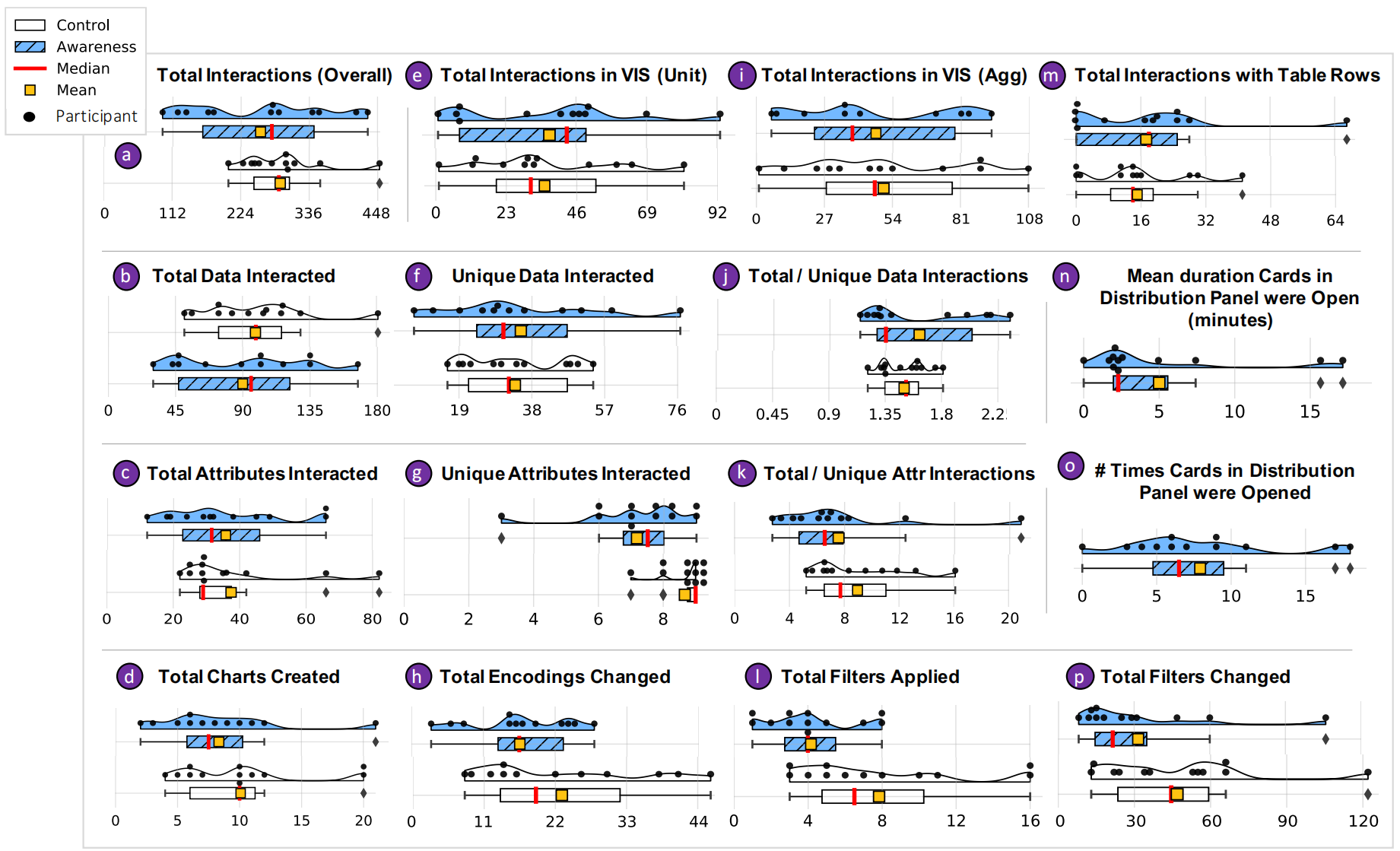
但是作者只观察到个别实验组的被试,在使用系统时因为开启了 interaction traces,从而使 bias(AD metrics)下降的情况(下图 D),大部分人并不会有意识的去控制 bias。
讨论
- 根据用户反馈,用颜色来编码交互痕迹似乎不妥,然而除了颜色也似乎没法
- target distribution:很难去描绘一个特定的 distribution
- 假阳性:用户会有意识的忽略一些东西,但系统会将它们标记出来
- 更多的缓解偏见的策略,被试提的一些小建议
- 学到的教训
- 好的系统需要通过增加 usability 来鼓励用户沉浸、深入地进行分析(get lost),但也需要能使用 awareness 来提醒用户发生了什么
- 虽然用户能够意识到偏见的产生,但系统本身并不能主动帮助用户修正分析行为(比如推荐数据)
- 不同的任务会有不同的目标分布
- 系统帮助修正用户的行为反而会招致用户对系统的控制力降低
限制
- 可视化形式较少
- 用户行为仅根据交互来建模
- 不同交互的权重一样
- 对于 aggregation visualization 的交互仅仅是简单的除以 N
我的看法
- 优点:
- 问题小,对 bias 的定义比较好,是对前作 (Warning, Bias May Occur) 的扩展
- evaluation 做的很好
- 开源
- 缺点:
- 容易被 challenge 文章的 novelty、contribution 不足的问题
- evaluation 在总体上对于 AD metrics 缺少衡量,因为结果不太好
- 一些创新想法?
- bias 的引起:数据本身、可视化编码、分析过程的覆盖率,甚至展示的硬件等
- bias 的类型:表格类型数据以外?数据探索的覆盖率以外的偏见?
- coverage:交互过 = covered?