神经元、层和前向传播:神经网络如何完成预测
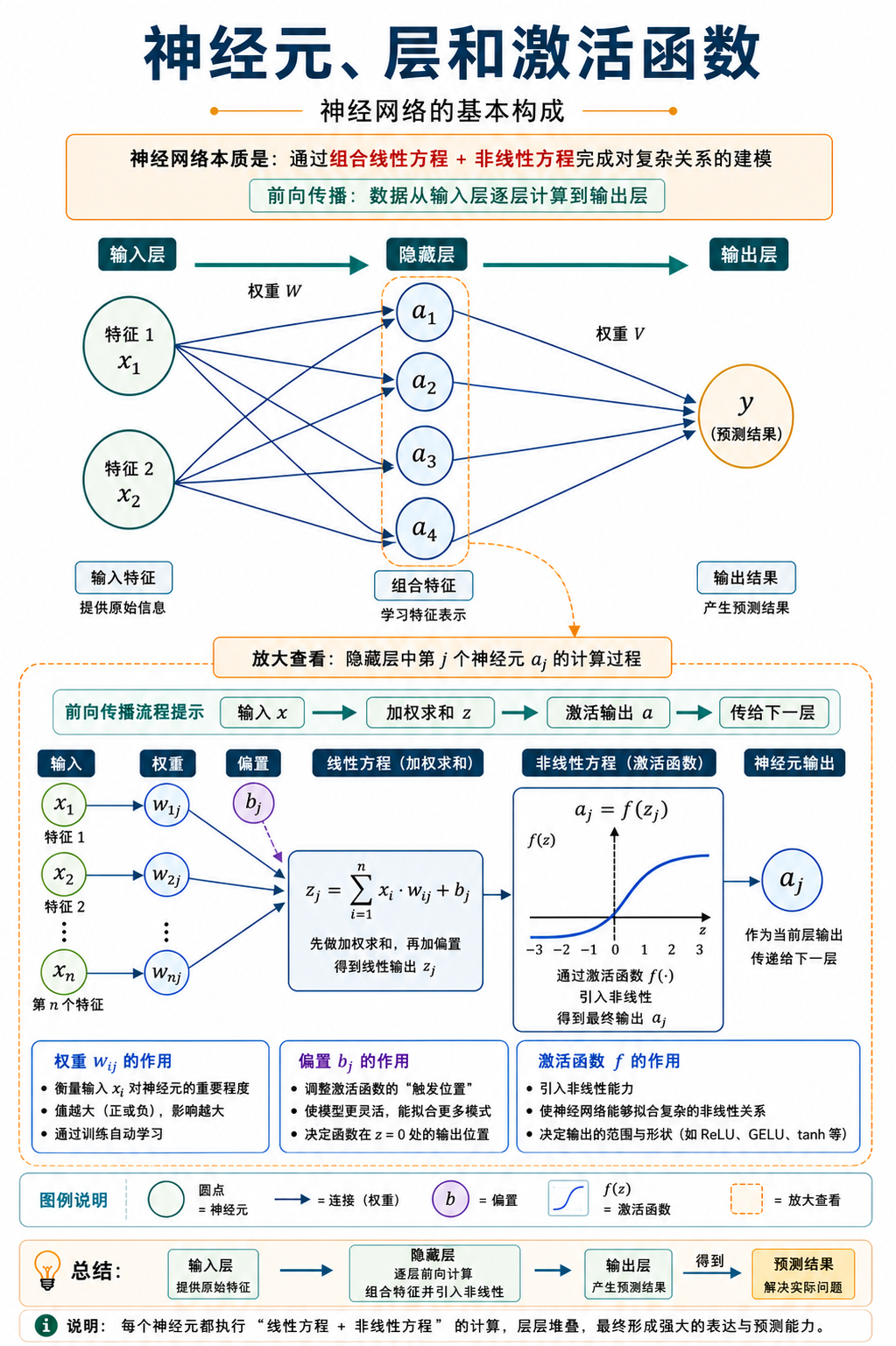
前面把神经网络理解成可以通过训练调整参数的预测函数:输入进去,经过内部计算,得到预测。这一篇继续往里看,先认识神经元、层和激活函数,再把它们连起来,看神经网络如何完成一次预测。
神经元可以先理解成一个小计算单元。它接收几个输入,把它们按不同重要性合在一起,再给出输出。多个神经元排在一起,就组成一层。层和层接起来,网络就能把原始输入加工成预测。
还是用小测预测的例子:
学习时长 = 2 小时
复习次数 = 1 次我们希望模型根据这两个输入,判断小测是否更可能通过。
一个神经元在做什么
可以把一个神经元想象成一个简化的“打分器”。它拿到学习时长和复习次数后,不是直接背答案,而是先给每个输入配一个重要性数字,再把结果加起来。
这个分数还不是经过激活函数之后的最终输出,可以先叫作“激活前分数”。最简单的形式可以写成:
激活前分数 = 输入1 × 权重1 + 输入2 × 权重2 + 偏置放回这个例子里,就是:
激活前分数 = 学习时长 × 权重1 + 复习次数 × 权重2 + 偏置当学习时长 = 2 小时、复习次数 = 1 次时,神经元会把这两个数字放进去,先算出激活前分数。分数越高,可能越倾向于“通过”;分数越低,可能越倾向于“不通过”。后面再经过激活函数,才得到这个神经元真正交给下一步的输出。
这里要抓住的直觉是:神经元不是手写规则表,而是用内部可以调整的数字,先把输入变成激活前分数,再得到后续输出。
权重和偏置
权重表示不同输入的重要性。
如果学习时长的权重比较大,就说明模型认为学习时长对预测结果影响更强。学习时长从 1 小时变成 2 小时,激活前分数可能变化明显。如果复习次数的权重比较小,就说明复习次数也有帮助,但影响相对小一些。
权重会在训练中调整。模型看过很多样本后,可能学到“学习时长更关键”,也可能学到“复习次数比想象中更重要”。这不是提前写死的。
偏置是模型可以调整的基础倾向。
只看权重时,输出主要跟输入一起变化。但模型有时还需要一个整体起点。比如小测很难时,模型可能更谨慎;小测很基础时,模型可能更容易给出高分。这个基础倾向就可以由偏置表示。
可以先这样记:
权重:每个输入有多重要
偏置:模型整体上的基础倾向多个神经元组成一层
一个神经元只能给出一个角度的中间分数。但同一个问题往往可以从多个角度看。
面对学习时长 = 2 小时、复习次数 = 1 次,某个神经元可能更关注学习时长,另一个神经元可能更关注复习次数,还有一个神经元可能整体更谨慎。它们看到的是同样的输入,却因为权重和偏置不同,得到不同的输出。
把多个神经元并排放在一起,就得到一层:
学习时长、复习次数 -> 神经元1 -> 输出1
学习时长、复习次数 -> 神经元2 -> 输出2
学习时长、复习次数 -> 神经元3 -> 输出3这一层会产生多个中间结果。后面的层再使用这些结果继续加工,最后形成预测。初学时可以简单记住:层就是一组神经元,它们一起接收输入,各自计算,再把结果交给后面。
为什么需要激活函数
到这里,一个神经元已经能把输入乘上权重,再加上偏置,得到激活前分数。那为什么还需要激活函数?
原因是:如果只有这种打分方式,网络不管堆多少层,整体上仍然很像一种简单直线关系。它能表达“学习越久,分数越高”这类趋势,但很难表达更有条件变化的关系。
现实里的预测常常不是一条直线。学习时长从 0 小时增加到 1 小时,帮助可能很大;从 5 小时增加到 6 小时,帮助可能就没那么明显。复习次数也类似,第一次复习可能特别有用,后面每多一次的提升可能逐渐变小。
激活函数就是放在激活前分数之后的一步处理。它会把原来的分数再变一下,得到神经元最终输出,让网络不只是简单直线关系,而是能表达更丰富的变化。
输入
-> 按权重和偏置算出激活前分数
-> 经过激活函数
-> 得到神经元的最终输出现在不需要记很多激活函数的名字,只要知道它的作用:让网络能够表达不只是直线关系的变化。
前向传播是什么
认识完神经元、层、权重、偏置和激活函数之后,就可以把这些部件连起来,看一次完整的预测计算。
前向传播,就是从输入一路算到输出的过程。“前向”表示信息的方向:先从原始输入开始,经过一层又一层的神经元加工,最后到达输出层,得到模型的预测。
输入 -> 中间层 -> 输出预测只要模型要给出预测,就会发生前向传播。训练模型时,每个样本都要先经过前向传播;训练完成后,真正使用模型时,也同样要经过前向传播。
输入如何进入网络
继续使用小测预测的例子。假设输入是:
学习时长 = 2
复习次数 = 1这里先不写单位,只把它们当作两个数字。它们会进入网络的第一层,交给这一层里的神经元。
一个神经元会把输入乘上自己的权重,再加上偏置,得到一个中间分数。先随便设一组数字:
学习时长的权重 = 0.6
复习次数的权重 = 0.8
偏置 = 0.1那么这个神经元会先算:
2 × 0.6 + 1 × 0.8 + 0.1 = 2.1这个 2.1 还不是最终预测,只是一个中间结果。接着它会经过激活函数。这里不展开具体激活函数公式,只是假设经过某个激活函数后得到:
神经元输出 = 0.89这表示原始输入已经被加工成了新的中间信息。
中间层如何加工信息
中间层里通常有多个神经元。它们看到同样的输入,但各自的权重和偏置不同,因此会得到不同结果。
比如第一层有三个神经元,它们可能分别算出:
神经元1输出 = 0.89
神经元2输出 = 0.55
神经元3输出 = 0.73这三个数字不再直接是“学习时长”和“复习次数”,而是第一层从输入里加工出的中间结果。
后面的层会继续使用这些数字。第二层看到的输入不再是原始的 2 和 1,而是上一层交过来的 0.89、0.55、0.73。第二层再用自己的权重和偏置处理它们,得到新的结果。
可以把这个过程想成一层层加工:前面的层离原始输入更近,后面的层离最终预测更近。无论层数多少,方向都不变:输入进入网络,信息向后传递,直到输出层给出预测。
输出层如何给出预测
输出层负责把前面加工后的信息,变成我们真正关心的预测。
在小测预测里,我们关心的是“是否通过”。在这个简化的二分类例子里,输出层可以先给出一个分数:
通过分数 = 0.78这个分数可以理解成模型倾向于“通过”的程度。为了得到更直观的结果,可以定一个简单规则:
如果通过分数 >= 0.5,就预测通过。
如果通过分数 < 0.5,就预测不通过。因为 0.78 大于 0.5,所以这一次前向传播得到的预测是:
学习时长 = 2
复习次数 = 1
-> 通过分数 = 0.78
-> 预测:通过从头看,这条小数字流程就是:输入两个数字,中间层继续加工,输出层给出分数,再得到“通过”这个预测。
前向传播还不知道自己对不对
前向传播只负责产生预测,不负责判断预测是否正确。
当前向传播结束时,模型只知道自己算出了什么,比如“预测通过”。但它还不知道这个预测是不是对的,还需要拿预测和真实答案比较。
可是“比较预测和真实答案”不是前向传播本身做的事情。前向传播到“输出预测”为止就结束了。训练时,后续步骤会根据预测和真实答案之间的差距,调整模型内部的数字;使用模型时,如果没有真实答案,模型也只是给出预测,不会自动知道自己准不准。
小结
神经元是一个小计算单元。它接收输入,用权重表示不同输入的重要性,再加上偏置这个基础倾向,先得到激活前分数:
激活前分数 = 输入1 × 权重1 + 输入2 × 权重2 + 偏置在小测预测中,输入是学习时长 = 2 小时、复习次数 = 1 次。权重决定模型更看重学习时长,还是更看重复习次数;偏置决定模型整体上更容易给出高分,还是更谨慎。
多个神经元并排组成一层,每个神经元可以从不同角度处理同一组输入。激活函数放在激活前分数之后,让网络能够表达不只是直线关系的变化。
前向传播则把这些部件串起来:输入进入第一层,中间层继续加工信息,输出层最后给出预测。它回答的是“模型现在会预测什么”,而不是“模型这次有没有预测对”。下一节的损失函数,才负责衡量预测和真实答案之间差了多少。
用代码理解:神经元、层和前向传播
下面用最少的 JavaScript 代码写出一次前向传播。它包含神经元、权重、偏置、激活函数、一层中的多个神经元,以及最后的输出层。
function sigmoid(x) {
return 1 / (1 + Math.exp(-x));
}
function neuron(inputs, weights, bias) {
var total = bias;
for (var index = 0; index < inputs.length; index = index + 1) {
// 第几个输入,就乘以第几个权重
total = total + inputs[index] * weights[index];
}
return sigmoid(total);
}
var inputs = [2, 1]; // 学习时长、复习次数
var hiddenWeights = [
[0.6, 0.8],
[0.4, -0.3],
[-0.2, 0.9],
];
var hiddenBiases = [0.1, 0.2, -0.1];
var hiddenLayer = [
neuron(inputs, hiddenWeights[0], hiddenBiases[0]),
neuron(inputs, hiddenWeights[1], hiddenBiases[1]),
neuron(inputs, hiddenWeights[2], hiddenBiases[2]),
];
var outputWeights = [1.0, -0.5, 0.7];
var outputBias = -0.3;
var output = neuron(hiddenLayer, outputWeights, outputBias);
console.log(
"中间层输出:",
hiddenLayer[0].toFixed(4),
hiddenLayer[1].toFixed(4),
hiddenLayer[2].toFixed(4)
);
console.log("通过分数:", output.toFixed(4));
console.log("预测结果:", output >= 0.5 ? "通过" : "未通过");这里的 neuron() 就是一个神经元。hiddenWeights 和 hiddenBiases 是中间层的参数;outputWeights 和 outputBias 是输出层的参数。hiddenLayer 里有三个神经元,所以它是一层。
前向传播就是从 inputs 开始,先算出中间层,再算出 output。整个过程只是在用当前参数做预测,还没有判断这次预测对不对。