如何衡量一个神经网络的好坏:损失函数
上一章说到,前向传播会把输入一步步变成预测。比如输入学习时长和复习次数,模型最后给出“通过”或“未通过”的判断,或者给出一个更细的分数。
可是训练时,只知道模型给出了预测还不够。我们还需要回答一个更关键的问题:这次预测到底好不好?
损失函数就是用来回答这个问题的工具。它会把模型的预测值和真实答案放在一起比较,然后算出一个数字。这个数字通常叫“损失”。损失函数让“模型表现好不好”变成可计算数字。
可以先把损失理解成一次打分,只不过这个分数不是奖励分,而是“错误程度分”。损失越小,表示模型预测得越接近真实答案;损失越大,表示预测越差。
所以,前向传播负责产生预测,损失函数负责评价预测。训练模型时,这两步经常连在一起出现:先预测,再计算这次预测错得有多严重。
预测值和真实答案
继续使用小测预测的例子。我们希望模型根据学习时长和复习次数,预测一个学生是否能通过小测。
为了让计算更方便,我们先把真实答案写成数字:
通过记为 1
未通过记为 0这里的 1 和 0 就是真实标签。真实标签不是模型猜出来的,而是数据里已经知道的答案。
假设某个学生的真实情况是通过小测,那么这个样本的真实标签就是:
真实标签 = 1模型经过前向传播后,不一定只输出“通过”或“未通过”这两个字。它也可以输出一个介于 0 和 1 之间的预测值,用来表示“通过的可能性有多大”。
例如模型预测:
预测通过概率 = 0.7
真实标签 = 1这表示模型认为这个学生有 0.7 的可能性通过,而真实答案确实是通过。直觉上,这个预测不算太差,因为 0.7 比较靠近 1。
如果模型预测通过概率是 0.2,而真实标签仍然是 1,那就明显更差。因为模型更倾向于认为学生不会通过,但真实答案却是通过。
用一个数字表示错得多严重
人可以凭直觉说:“0.7 对 1,比 0.2 对 1 更好。”但是模型训练不能只靠直觉,它需要一个明确的数字。
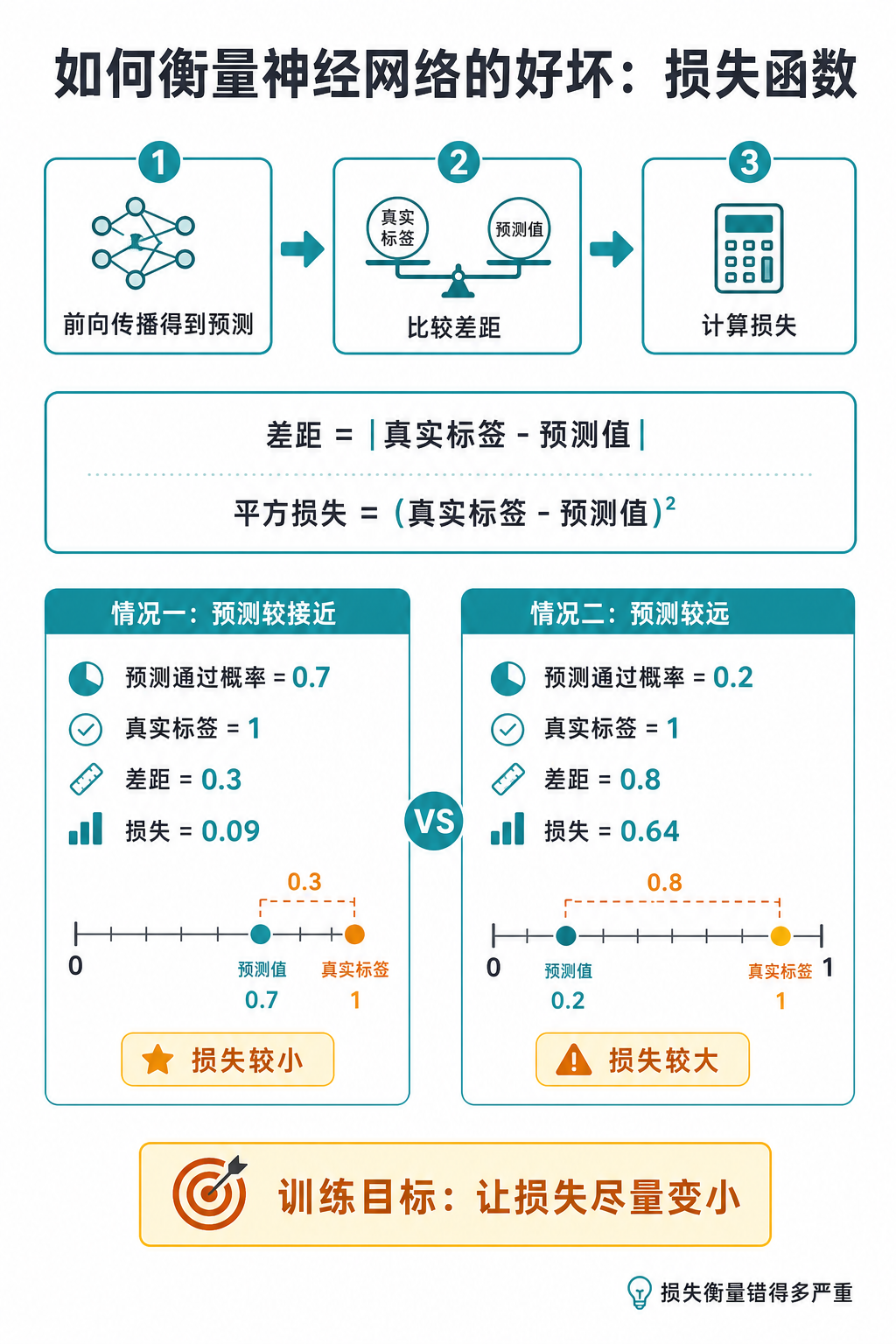
损失函数做的事情,就是把这种差距变成一个数字。最直观的做法,是先看真实标签和预测值之间差多少:
差距 = |真实标签 - 预测值|差距越小,说明预测越接近真实答案;差距越大,说明预测越远。
常见的损失函数会进一步把这个差距平方。这样不仅能得到一个非负数字,还会让较大的错误变得更显眼:
损失 = (真实标签 - 预测值)^2这叫平方损失。它不是唯一的损失函数,但很适合用来建立第一层直觉。
看下面两个情况:
情况一:
预测通过概率 = 0.7
真实标签 = 1
差距 = |1 - 0.7| = 0.3
损失 = 0.3^2 = 0.09
情况二:
预测通过概率 = 0.2
真实标签 = 1
差距 = |1 - 0.2| = 0.8
损失 = 0.8^2 = 0.64这两个数字就把直觉变得更明确了:0.7 离 1 比较近,所以损失是 0.09;0.2 离 1 比较远,所以损失是 0.64。
如果模型预测通过概率是 0.99,真实标签是 1,那么预测很接近真实答案,损失会很小。如果模型预测通过概率是 0.01,真实标签是 1,那么预测方向几乎完全相反,损失会很大。
因此,损失不是单纯判断“对”或“错”。它还能表达错得轻还是错得重,把这种差别记录成一个数字。
损失给训练提供方向
训练模型的目标,不是让模型只完成一次预测,而是让它在很多样本上逐渐变好。
可是“变好”这个说法太模糊了。模型需要知道:现在这样预测到底离目标有多远?下一次调整之后有没有更接近目标?
损失函数提供的数字,就能帮助回答这些问题。
如果一次调整后,整体损失变小了,说明模型的预测通常更接近真实答案了。这样的调整大概率是有帮助的。
如果一次调整后,整体损失变大了,说明模型的预测通常离真实答案更远了。这样的调整就可能不合适。
可以把训练想成不断调整模型内部的权重和偏置。每次调整之后,模型重新前向传播,得到新的预测;再用损失函数比较预测值和真实标签,得到新的损失。这样,训练过程就有了可以观察的目标:让损失尽量变小。
当然,一个样本的损失只能说明这一次预测的情况;很多样本合在一起,才能更稳定地反映模型整体表现。
本章不展开复杂公式
损失函数有很多种。不同任务会选择不同的损失函数,有的适合预测数值,有的适合判断类别,有的适合更复杂的目标。
但在这一章,我们只用平方损失建立第一层理解:
损失 = (真实标签 - 预测值)²也就是说,损失函数不是把预测值和真实标签简单相加,而是比较它们之间的差距,再把差距变成一个数字。这个数字越大,通常表示模型这次预测越差;这个数字越小,通常表示模型这次预测越好。
等理解了这个位置,再去看其他损失函数会轻松很多:不同公式只是在用不同方式衡量预测和真实答案之间的差距。
小结
前向传播让模型给出预测,但它不会判断预测是否正确。损失函数接在预测之后,用来比较预测值和真实答案,并把差距变成一个可以计算的数字。
在小测预测中,我们可以把真实标签设定为:通过记为 1,未通过记为 0。如果模型预测通过概率是 0.7,真实标签是 1,那么平方损失就是 (1 - 0.7)^2 = 0.09,说明预测比较接近真实答案,损失相对较小。
损失越大,表示预测越差;损失越小,表示预测越接近真实答案。训练模型时,我们会观察损失如何变化,并努力让损失变小。这样,“模型表现好不好”就不再只是模糊感觉,而是变成了训练过程可以使用的数字。
用代码理解:损失函数把错误变成数字
下面用平方损失比较几次预测。真实标签是 1,表示这个学生确实通过了小测。
function squaredLoss(prediction, target) {
var error = target - prediction;
return error * error;
}
var target = 1;
var predictions = [0.99, 0.7, 0.2, 0.01];
for (var index = 0; index < predictions.length; index = index + 1) {
var prediction = predictions[index];
var loss = squaredLoss(prediction, target);
console.log("预测值:", prediction, "损失:", Number(loss.toFixed(4)));
}输出里的损失越小,说明预测越接近真实答案。0.99 离 1 很近,所以损失很小;0.01 离 1 很远,所以损失很大。
这就是损失函数的核心作用:把“预测得好不好”变成一个可以比较、可以优化的数字。