如何训练一个神经网络
前面几节先讲了神经网络的构成、如何完成预测,以及如何用损失函数衡量预测好坏。
现在进入训练视角。
训练要解决的问题不是“模型如何算出一个输出”,而是:
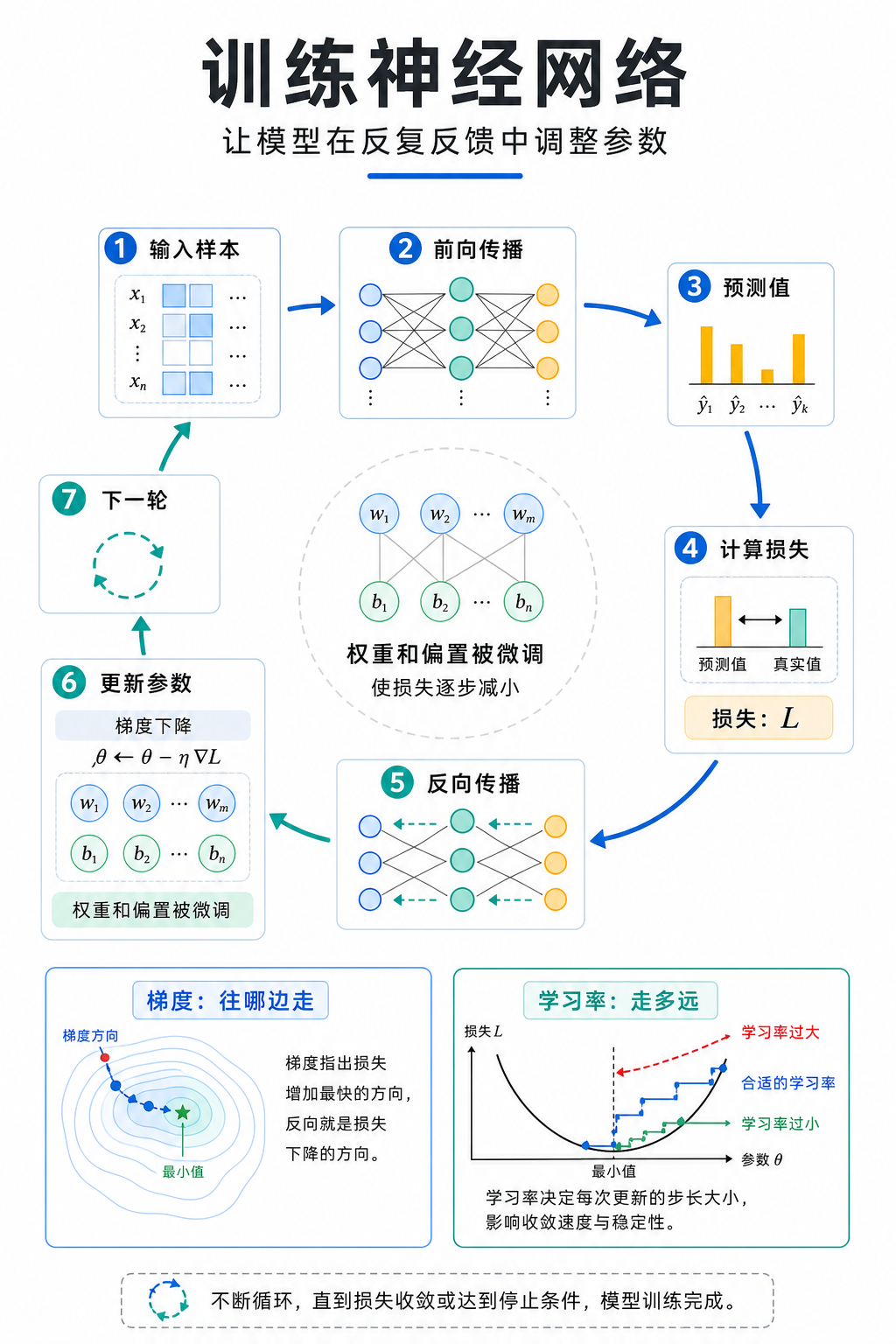
模型预测得不够好时,内部参数应该怎样调整?训练不是一次操作,而是一个反复循环。模型先用当前参数完成一次前向传播,得到预测;再用损失函数比较预测和真实答案,得到损失;然后把错误信号传回参数,最后更新参数。更新之后,模型再进入下一轮。
可以先记住这个闭环:
预测 -> 计算损失 -> 回溯错误 -> 更新参数 -> 再预测训练从一次预测开始
继续使用小测预测的例子。输入可能是:
学习时长 = 2
复习次数 = 1模型先进行前向传播,根据当前权重和偏置给出预测:
预测通过概率 = 0.3如果真实答案是通过,也就是目标更接近 1,那么 0.3 就明显偏低。损失函数会把这个差距变成一个数字,告诉训练过程:这次预测错得比较严重。
用代码写出来,就是先用当前参数预测,再计算损失:
function predict(studyHours, reviewTimes, weightStudy, weightReview, bias) {
return studyHours * weightStudy + reviewTimes * weightReview + bias;
}
var sample = {
"studyHours": 2,
"reviewTimes": 1,
"target": 1,
};
var weightStudy = 0.1;
var weightReview = 0.1;
var bias = 0.0;
var prediction = predict(
sample["studyHours"],
sample["reviewTimes"],
weightStudy,
weightReview,
bias
);
var error = prediction - sample["target"];
var loss = error * error;
console.log("预测:", prediction.toFixed(4));
console.log("损失:", loss.toFixed(6));到这里,模型已经知道“预测不好”。但训练还不能停在这里,因为它还不知道应该改哪些参数。
反向传播:把错误传回参数
神经网络里通常有很多层,也有很多权重和偏置。最后的预测值,是所有这些参数共同作用后的结果。
如果只知道“预测太低”,还不足以更新整个网络。因为一个错误结果背后,可能有很多参数参与。训练过程需要继续追问:
哪些参数对这次错误影响更大?
它们大致应该往哪个方向改?反向传播就是用来回答这个问题的方法。
前向传播时,信息从输入层流向输出层;反向传播时,错误信号从输出层往输入方向传回去。它会沿着前向传播留下的计算关系,把最终错误拆回到各个环节。
可以把它理解成一次复盘:
前向传播:做题过程
损失函数:批改结果
反向传播:回看步骤,分配责任反向传播不是把错误平均分给所有参数。不同权重对错误的影响不同。有的权重连接着这次样本里很重要的信号,稍微改动就会明显影响输出;有的权重这次几乎没有发挥作用,它对错误的责任就小。
在小测预测中,如果学习时长和复习次数都显示学生很可能通过,但模型仍然预测很低,那么与这些积极信号相关的连接,可能需要承担更多责任。反向传播会根据前向传播时每个信号实际参与的程度,给不同参数分配不同大小、不同方向的调整线索。
在这个极简例子里,模型只有三个参数,所以可以把反向传播先简化成计算三个梯度:
先把预测函数和损失函数写成公式:
其中, 是学习时长, 是复习次数, 和 是两个权重, 是偏置, 是预测值, 是真实答案。
我们想知道每个参数对损失 的影响有多大。可以分两步看。
第一步,先看损失 对预测值 的变化有多敏感。因为 ,所以:
第二步,再看预测值 对每个参数的变化有多敏感。因为:
所以:
第三步,把这两步乘起来,也就是链式法则:
代码里的 error 就是 ,所以三个梯度会写成 2 * error * 输入值,偏置没有对应输入,就写成 2 * error。
var sample = {
"studyHours": 2,
"reviewTimes": 1,
"target": 1,
};
var prediction = 0.3;
var error = prediction - sample["target"];
// 反向传播在这里被简化成三个参数各自的梯度
var gradientStudy = 2 * error * sample["studyHours"];
var gradientReview = 2 * error * sample["reviewTimes"];
var gradientBias = 2 * error;
console.log("学习时长权重的梯度:", gradientStudy.toFixed(4));
console.log("复习次数权重的梯度:", gradientReview.toFixed(4));
console.log("偏置的梯度:", gradientBias.toFixed(4));输入越大、误差越大,对应权重这次需要调整的幅度也越大。这里的梯度不是最终参数,而是告诉训练过程:每个参数大致应该往哪个方向改、改多少。
梯度下降:沿着损失变小的方向走
反向传播提供调整线索之后,还需要真正修改参数。梯度下降就是负责做这件事的一种方法。
它的目标很直接:
不断调整参数,让损失尽量变小。可以把损失想象成一座山上的高度。参数的位置不同,损失的高度也不同。训练的目标不是爬到更高的地方,而是往更低的地方走。梯度提供方向信息,帮助我们判断参数往哪边改,可能会让损失变小。
继续看小测例子。假设真实标签是 1,模型预测通过概率只有 0.3。这个预测太低,说明模型对“会通过”的判断不够强。梯度会帮助训练过程判断,哪些权重应该往上调,哪些权重应该往下调,哪些参数暂时只需要很小的变化。
这不是说所有权重都要一起变大。某些权重调大可能有帮助,某些权重调大反而可能让别的样本预测变差。梯度下降做的事情,是借助损失给出的反馈,沿着整体上更可能让损失变小的方向更新参数。
学习率:每次更新走多远
知道方向还不够,还要决定每次走多大一步。这个“步子大小”由学习率控制。
学习率决定每次更新参数时,根据梯度判断出的更新方向移动多少。学习率大,参数每次变化就大;学习率小,参数每次变化就小。
如果学习率太大,模型可能一下子跨过了比较好的位置,损失反而忽高忽低。如果学习率太小,模型每次只挪动一点点,训练会很慢。
所以,可以这样记:
梯度:往哪边走
学习率:走多远两者配合起来,才形成一次具体的参数更新。
下面这段代码只做一次梯度下降更新。它先像前面一样算出预测和梯度,再把学习率乘到梯度上,控制这次参数变化的大小:
function predict(studyHours, reviewTimes, weightStudy, weightReview, bias) {
return studyHours * weightStudy + reviewTimes * weightReview + bias;
}
var sample = {
"studyHours": 2,
"reviewTimes": 1,
"target": 1,
};
var weightStudy = 0.1;
var weightReview = 0.1;
var bias = 0.0;
var learningRate = 0.1;
var prediction = predict(
sample["studyHours"],
sample["reviewTimes"],
weightStudy,
weightReview,
bias
);
var error = prediction - sample["target"];
// 先复用前面的反向传播公式,算出梯度
var gradientStudy = 2 * error * sample["studyHours"];
var gradientReview = 2 * error * sample["reviewTimes"];
var gradientBias = 2 * error;
// 往梯度方向更新一个学习率长度的 step
weightStudy = weightStudy - learningRate * gradientStudy;
weightReview = weightReview - learningRate * gradientReview;
bias = bias - learningRate * gradientBias;
console.log("更新前预测:", prediction.toFixed(4));
console.log("学习时长权重的梯度:", gradientStudy.toFixed(4));
console.log("复习次数权重的梯度:", gradientReview.toFixed(4));
console.log("偏置的梯度:", gradientBias.toFixed(4));
console.log("更新后的学习时长权重:", weightStudy.toFixed(4));
console.log("更新后的复习次数权重:", weightReview.toFixed(4));
console.log("更新后的偏置:", bias.toFixed(4));因为这次预测偏低,梯度会让相关参数变大一些。参数一变,下一次用同样输入做预测时,输出分数也会变。
训练循环:反复预测和订正
参数通常不是一次就能调好的。刚开始时,模型内部的数字还不合适,可能把该通过的学生预测成不通过,也可能对某些样本只是碰巧猜对。
如果只训练一轮,模型得到的反馈太少,调整也太少。就像做题只订正一次,很难马上掌握一类题。模型需要反复经历“预测、计算损失、回溯错误、更新参数、再预测”,才能形成更稳定的判断。
完整训练流程可以写成:
准备样本和真实答案
-> 使用当前参数进行前向传播
-> 得到预测
-> 用损失函数比较预测和真实答案
-> 得到损失,知道错误程度
-> 通过反向传播把错误信号传回各层
-> 通过梯度下降更新参数
-> 进入下一轮参数更新后,同一个输入也可能得到不同预测。原因很直接:前向传播依赖权重和偏置;这些数字变了,输出分数也可能变。
例如同一个学生,更新前可能是:
学习时长 = 2
复习次数 = 1
预测通过概率 = 0.3更新后再输入同样的信息,结果可能变成:
预测通过概率 = 0.45这不代表模型已经完全正确,只说明参数变化会影响之后的预测。很多次小调整累积起来,模型才有机会逐渐变好。
把前面的几步放进循环里,就得到一个最小训练过程:
function predict(studyHours, reviewTimes, weightStudy, weightReview, bias) {
return studyHours * weightStudy + reviewTimes * weightReview + bias;
}
var sample = {
"studyHours": 2,
"reviewTimes": 1,
"target": 1,
};
var weightStudy = 0.1;
var weightReview = 0.1;
var bias = 0.0;
var learningRate = 0.1;
for (var step = 0; step < 10; step = step + 1) {
var prediction = predict(
sample["studyHours"],
sample["reviewTimes"],
weightStudy,
weightReview,
bias
);
var error = prediction - sample["target"];
var loss = error * error;
// 反向传播:计算每个参数对应的梯度
var gradientStudy = 2 * error * sample["studyHours"];
var gradientReview = 2 * error * sample["reviewTimes"];
var gradientBias = 2 * error;
// 梯度下降:按照学习率更新参数
weightStudy = weightStudy - learningRate * gradientStudy;
weightReview = weightReview - learningRate * gradientReview;
bias = bias - learningRate * gradientBias;
console.log("第", step + 1, "轮", "预测:", prediction.toFixed(4), "损失:", loss.toFixed(6));
}
console.log("训练后的参数:", weightStudy.toFixed(4), weightReview.toFixed(4), bias.toFixed(4));这个例子里,第一次预测通常离真实答案比较远,所以损失较大。每轮更新后,参数都会发生一点变化,后面的预测会总体逐渐接近 target = 1。
真实神经网络会有更多层、更多参数和更复杂的反向传播,但基本闭环仍然是:先预测,再根据损失更新参数。
小结
训练神经网络,就是让模型在反复反馈中调整参数。
前向传播先得到预测,损失函数衡量预测和真实答案的差距。反向传播把错误信号从输出层往前传,帮助每个参数得到自己的调整线索。梯度下降再根据这些线索和学习率更新参数。
可以把训练记成:
预测 -> 计算损失 -> 反向传播 -> 梯度下降 -> 再预测推理只需要前向传播;训练则需要在前向传播之后继续计算损失、回溯错误并更新参数。理解了这个区别,就能把本章的概念分成两类:一类负责完成预测,另一类负责让预测变得更好。