语言模型:预测下一个词
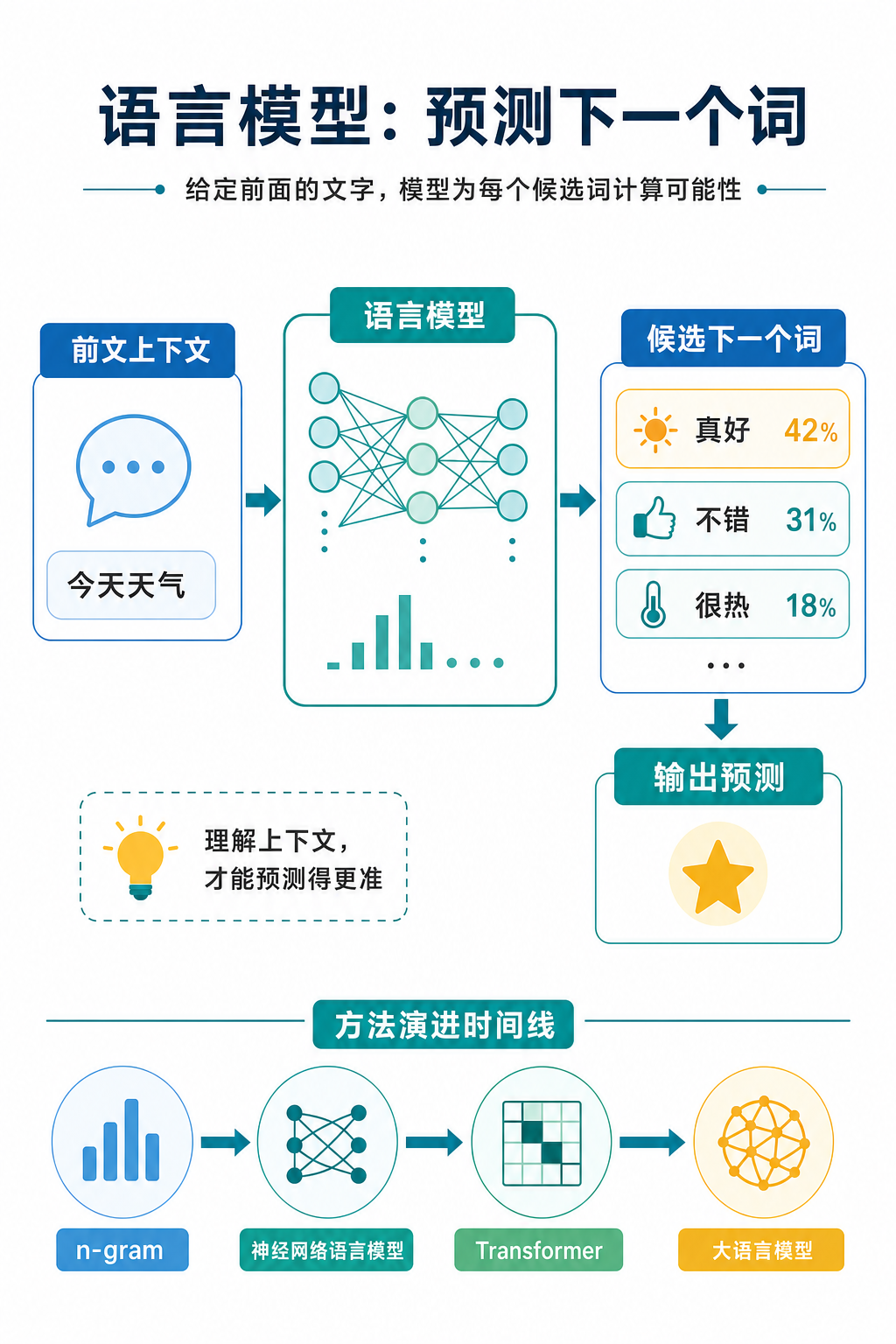
你在手机上打字的时候,键盘上方经常会冒出一排候选词。你刚输入"今天天气",手机就建议"真好""不错""怎么样"。你选了一个,手机又接着猜下一个。
这个功能背后就是语言模型在做的事:给定前面的文字,预测下一个词。
今天天气 -> ?模型给出的答案可能是"真好",可能是"不错",也可能是别的。它会为每个可能的词算一个可能性,然后把最可能的几个展示出来。
这不只是输入法在用。搜索引擎的自动补全、聊天软件的回复建议,甚至你用来对话的大语言模型,核心思路都一样:看前面的内容,猜接下来会说什么。
语言模型也是一种预测
还记得第 00 章说的预测吗?那时我们用学习时长和复习次数来预测小测是否通过。模型拿到输入,经过内部计算,给出一个预测结果。
语言模型也是在做预测,只不过现在预测的不是小测是否通过,而是下一个词是什么。
第 00 章:学习时长、复习次数 -> 模型 -> 是否通过
这一章:今天天气 -> 模型 -> 下一个词输入从数字变成了文字,输出从一个判断变成了一个词,但本质上都是:给模型一些信息,让它给出一个预测。
为什么预测下一个词就算"理解"语言
乍一看,"预测下一个词"好像只是个猜谜游戏。但仔细想想:要准确预测下一个词,模型必须理解前面说了什么。
比如这句话:
小明今天发烧了,所以他没去____要填对这个词,你得知道:发烧是一种生病的状态,生病的人通常不会去学校或上班,"没去"后面跟着的应该是某个日常场所。正确的答案很可能是"学校"。
再比如:
虽然今天下了大雨,但是我们还是____要预测这里下一个词,你得理解"虽然...但是..."表示转折,前半句说天气不好,后半句应该表达"还是做了某件事"。可能的答案是"去了""出发了"之类。
这两个例子说明一件事:要猜对下一个词,模型不能只是机械地统计词频,它需要理解上下文的意思。
一个只会背统计数字的模型可能会觉得"吃饭"经常出现,于是在"他没去"后面也建议"吃饭"。但一个真正理解上下文的模型会知道,这里填"学校"才合理。
这就是为什么"预测下一个词"可以成为语言理解的基础:预测得越准,说明模型对语言的理解越深。
语言模型是怎么变强的
最早的语言模型用的是一种很直觉的方法:统计。
比如模型看到"今天天气"后面跟着"真好"出现了 50 次,"不错"出现了 30 次,"很热"出现了 20 次。那下次再看到"今天天气",就把"真好"排在第一个。
这种方法叫 n-gram。它直接从文本里统计"几个词连在一起出现了多少次",然后用这个统计结果来预测。思路很直接,效果也不错,但有一个明显的问题:它只能看到很短的上下文。
如果只统计两个词的组合(bigram),模型就只看前一个词。比如看到"天气",就猜下一个词是什么,完全不管前面说的是"今天"还是"明天"还是"我不关心"。如果统计三个词的组合(trigram),模型能看到前两个词,但还是不够。
bigram:只看前 1 个词
trigram:只看前 2 个词
4-gram:只看前 3 个词再往上,组合数量会爆炸式增长,而且很多组合在训练文本里从来没出现过,统计就失效了。
后来人们开始用神经网络来做语言模型。神经网络不需要事先统计所有可能的组合,而是通过训练,学会从上下文中提取有用的信息。无论上下文有多长,神经网络都可以尝试从中找到规律,而不只是数"这几个词一起出现过几次"。
再后来, Transformer 结构出现了,它让模型能更好地关注上下文中不同位置的信息。基于 Transformer 的大语言模型能处理非常长的文本,在"预测下一个词"这个任务上达到了前所未有的水平。
这些细节后面会逐步展开。现在只需要记住一条线索:
统计方法(n-gram)-> 神经网络语言模型 -> Transformer -> 大语言模型每一次演进,模型都能看到更长的上下文,做出更准确的预测。
一个小实验
你可以试着做一个"人肉语言模型"。找一段文字,遮住最后一个词,看看自己能不能猜对:
这家餐厅的菜很好吃,就是价格有点____你大概会猜"贵"。因为"好吃"是正面评价,"就是"表示转折,后面应该是负面的,而跟"价格"搭配的负面评价最常见的就是"贵"。
你在做这个猜测的时候,其实就在做语言模型做的事:理解上下文,预测下一个词。而且你做得很好,因为你理解这些词的意思,理解句子的结构,还理解"好吃但价格高"是一种常见的评价模式。
语言模型想要做到的,就是把这种理解能力学会。
但文字不是数字
到这里,语言模型的任务已经很清楚了:给一段文字,预测下一个词。
但有个问题。还记得第 00 章说的吗?神经网络只能处理数字。它不认识"今天",不认识"天气",更不认识"真好"。它内部的权重、偏置、前向传播,全都是在数字上操作的。
所以,要训练一个神经网络语言模型,首先得解决一个问题:文字怎么变成数字?
这个问题很重要,它直接影响模型能学到什么。下一节就来聊这件事。