从文字到数字:Tokenizer 和 Embedding
上一节末尾留了一个问题:语言模型的输入是文字,但神经网络只认数字。那文字怎么变成数字?
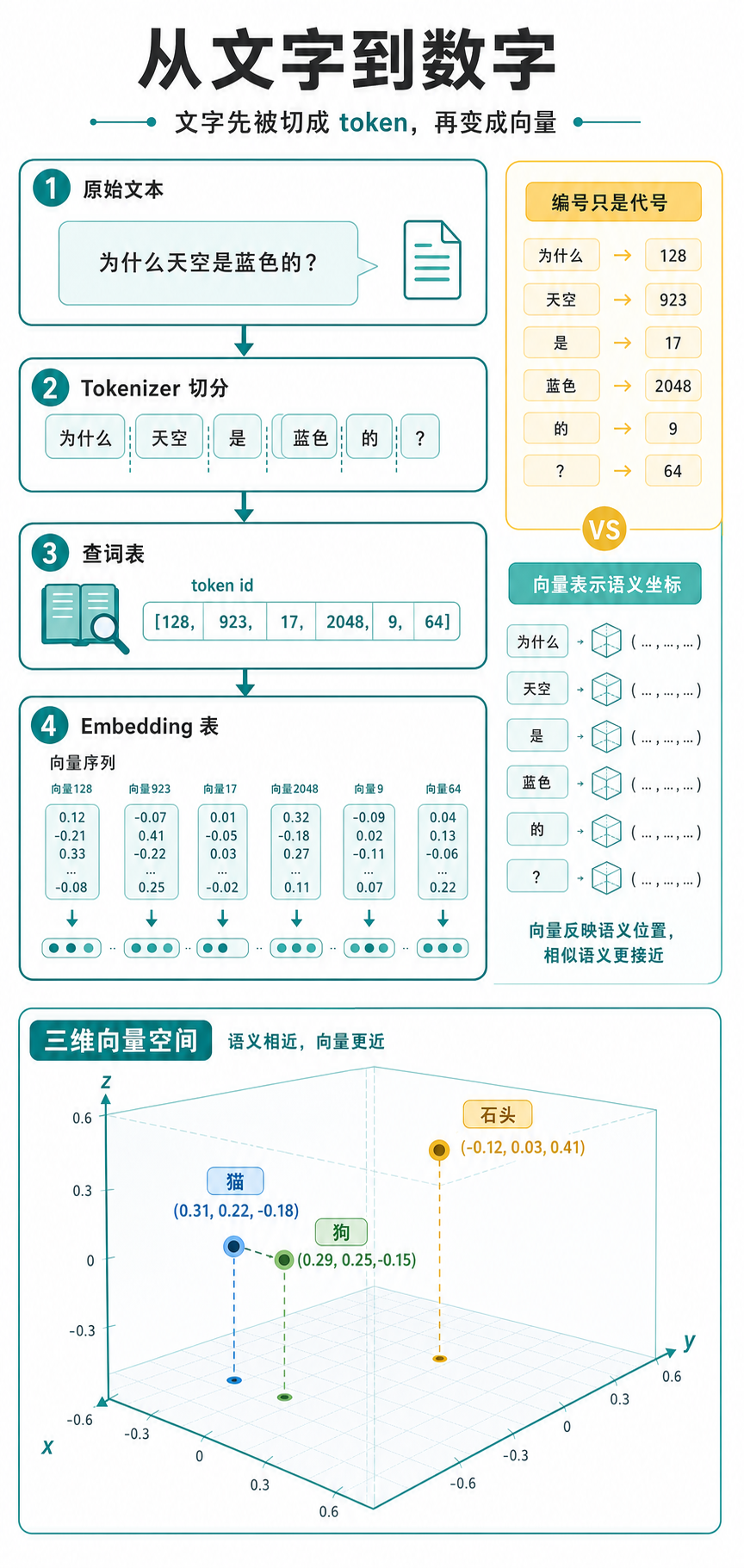
这一节就来回答这个问题。整个过程分两步:先把文字切成小块并编号,再把编号变成有意义的向量。
第一步:把文字切成 token
神经网络不认识"今天天气真好"这串文字。要让它能处理,首先得把文字拆成更小的单位。
这个拆分出来的单位叫做 token。Token 不等于一个字,也不等于一个词。它更像是一种介于字和词之间的东西。
用一句话试试:
原始文本:为什么天空是蓝色的?
切分成 token:
为什么 / 天空 / 是 / 蓝色 / 的 / ?这里"为什么"被当作一个 token,"天空"是一个 token,"是"是一个 token,"蓝色"是一个 token。注意"蓝"和"色"没有被拆开,而"为什么"三个字也被合在了一起。
换成英文看看:
原始文本:Why is the sky blue?
切分成 token:
Why / is / the / sky / blue / ?英文看起来更像是按词切的,但也不完全一样。有些词会被拆开:
原始文本:unbelievable
切分成 token:
un / believ / able所以 token 的切分方式不完全是按词,也不完全是按字,而是按一套训练出来的规则来切的。这套规则的目标是:用尽量少的 token 覆盖尽量多的文本。
词表:所有 token 的字典
一种语言里有成千上万个词,但 token 的数量是有限的。模型会维护一个"词表"(vocabulary),里面列出了所有它能识别的 token。
假设词表里有 50000 个 token,那每个 token 就有一个编号,从 0 到 49999:
token id
--------------
为什么 128
天空 923
是 17
蓝色 2048
的 9
? 64
...这个词表是提前建好的。训练 tokenizer 的时候,系统会从大量文本中统计出最常见的文本片段,把它们收进词表。
整体流程
把文字变成数字编号,整个过程就是:
原始文本:为什么天空是蓝色的?
↓ tokenizer 切分
token 列表:[为什么, 天空, 是, 蓝色, 的, ?]
↓ 查词表得到 id
token id 列表:[128, 923, 17, 2048, 9, 64]文字就这样变成了一串数字。但问题来了:这串数字只是编号,本身没有任何含义。
第二步:让编号有意义
128 代表"为什么",923 代表"天空",17 代表"是"。这些数字只是分配的编号,就像学号一样。学号 128 的同学和学号 923 的同学之间,学号的大小并不代表任何关系。
但模型需要理解 token 之间的关系。"天空"和"蓝色"语义上有关联,"猫"和"狗"都是动物,这些关系用单个数字编号是表达不出来的。
Embedding 表:一张查表
解决办法是给每个 token 分配一个向量,而不是一个数字。这个向量是一串小数,比如 256 维或 512 维的。
可以把这想象成一张大表:
token id embedding 向量
-----------------------------
0 [0.05, -0.12, 0.33, ...]
1 [0.21, 0.08, -0.15, ...]
...
128 [0.12, -0.38, 0.07, ...] ← "为什么"
...
923 [0.03, 0.51, -0.22, ...] ← "天空"
...
2048 [0.19, 0.47, -0.09, ...] ← "蓝色"输入一个 token id,查这张表,就能得到一行向量。这个过程叫 embedding。
如果词表大小是 ,每个向量有 维,那这张表就是一个 的大矩阵。查表的过程就是拿着 id 去矩阵里取对应的那一行。
这些向量一开始就有意义吗
没有。
训练刚开始的时候,这张表里的每一个向量都是随机数。"天空"的向量和"蓝色"的向量之间没有任何关系,跟"石头"的向量也没有区别。
但在训练过程中,模型会不断调整这些向量。每做一次预测,如果预测得不够好,模型就会微调相关 token 的向量,让它们往更好的方向移动。
经过大量文本的训练之后,有意思的事情会发生:语义相近的 token,向量会变得接近。
猫 -> [0.31, 0.22, -0.18, ...]
狗 -> [0.29, 0.25, -0.15, ...]
石头 -> [-0.12, 0.03, 0.41, ...]"猫"和"狗"的向量比较接近,因为它们经常出现在相似的上下文里:"猫喜欢吃鱼""狗喜欢吃肉","我家养了一只猫""我家养了一只狗"。训练过程中,模型从这些相似的用法里学到了它们之间的联系。
这不是人手工告诉模型"猫和狗都是动物"。模型只是通过大量文本中的上下文关系,自然而然地把相似的 token 映射到了向量空间中相近的位置。
整体流程更新
现在完整的流程变成了:
原始文本:为什么天空是蓝色的?
↓ tokenizer 切分 + 查词表
token id 列表:[128, 923, 17, 2048, 9, 64]
↓ 查 embedding 表
向量序列:
向量128 ← "为什么"
向量923 ← "天空"
向量17 ← "是"
向量2048 ← "蓝色"
向量9 ← "的"
向量64 ← "?"文字就这样变成了一串有意义的向量。每个 token 不再只是一个编号,而是一个在语义空间中有位置的点。
回顾
把文字变成模型能处理的数字,分两步走:
文字 → token → token id → embedding 向量第一步,tokenizer 把文字切成 token,查词表得到编号。这一步解决了"文字怎么变成数字"的问题,但得到的只是无意义的编号。
第二步,embedding 表把编号变成向量。这些向量一开始是随机数,在训练中逐渐学出语义关系。
现在文字变成了数字向量,自然可以喂给神经网络了。那下一个问题就来了:用第 00 章学的简单神经网络来处理这些向量,够用吗?