大模型:为什么要"大"
前面几节我们聊了语言模型的基本原理:把文字变成数字,用注意力机制理解上下文,用 Transformer 架构一个词一个词地生成。这些机制听起来都不算特别复杂,那为什么现在的大语言模型需要那么多显卡、那么多钱、那么多人来训练?
答案很简单,也很让人意外:因为"大"本身就会带来质变。
从小到大的演进
我们先看一条简短的时间线。
2018 年,GPT-1 发布,参数量大约 1 亿多。它能做一些简单的语言任务,但效果平平,没有人觉得它会改变什么。
2019 年,GPT-2 把参数量提升到了 15 亿,大约是 GPT-1 的十多倍。它写出来的文字开始像模像样了,能连贯地续写一段故事,但逻辑还经常出错。
2020 年,GPT-3 的参数量达到了 1750 亿,又是一个百倍的跳跃。这一次,人们开始惊讶了:它不仅能写流畅的文章,还能做翻译、回答问题、甚至写简单的代码。
再后来,GPT-4 的具体规模没有公开,但从表现来看,它又上了一个台阶。它能处理更复杂的推理,犯更少的错误,在各种各样的任务上都表现得越来越可靠。
GPT-1 ~1 亿参数 -> 能用,但不起眼
GPT-2 ~15 亿参数 -> 写文字开始像样
GPT-3 ~1750 亿参数 -> 让人惊讶
GPT-4 更大 -> 让人认真思考未来注意这条时间线上的量级变化。从 1 亿到 15 亿,大约十多倍;从 15 亿到 1750 亿,超过一百倍;后面还在继续增长。每一次量级的跳跃,都伴随着能力的明显提升。
"大"意味着什么
说一个模型"大",到底是在说什么?主要是两件事。
第一是参数量。还记得第 00 章说的"旋钮"吗?模型内部有大量的参数,每个参数就像一个小旋钮,控制着模型的行为。参数越多,模型能学到的模式就越复杂。从 1 亿个旋钮到 1750 亿个旋钮,意味着模型有更精细的调整空间。
第二是训练数据量。小模型可能只用几千本书来训练,而大模型几乎读了整个互联网能找到的文字:网页、书籍、论文、代码、百科、论坛讨论......从几本书到整个互联网,模型见过的文本量也是指数级增长的。
这两件事缺一不可。光有参数没有数据,就像给了一个人超大的大脑但什么都不让他学,白白浪费了容量。光有数据没有参数,就像让一个人读了一辈子书但大脑太小装不下,学了也记不住。参数量和数据量必须一起增长,模型才会真正变强。
参数量:模型内部的"旋钮"数量,决定能学多复杂的模式
数据量:模型见过的文本数量,决定有多少东西可学
两者一起增长,缺一不可涌现能力:量变引起质变
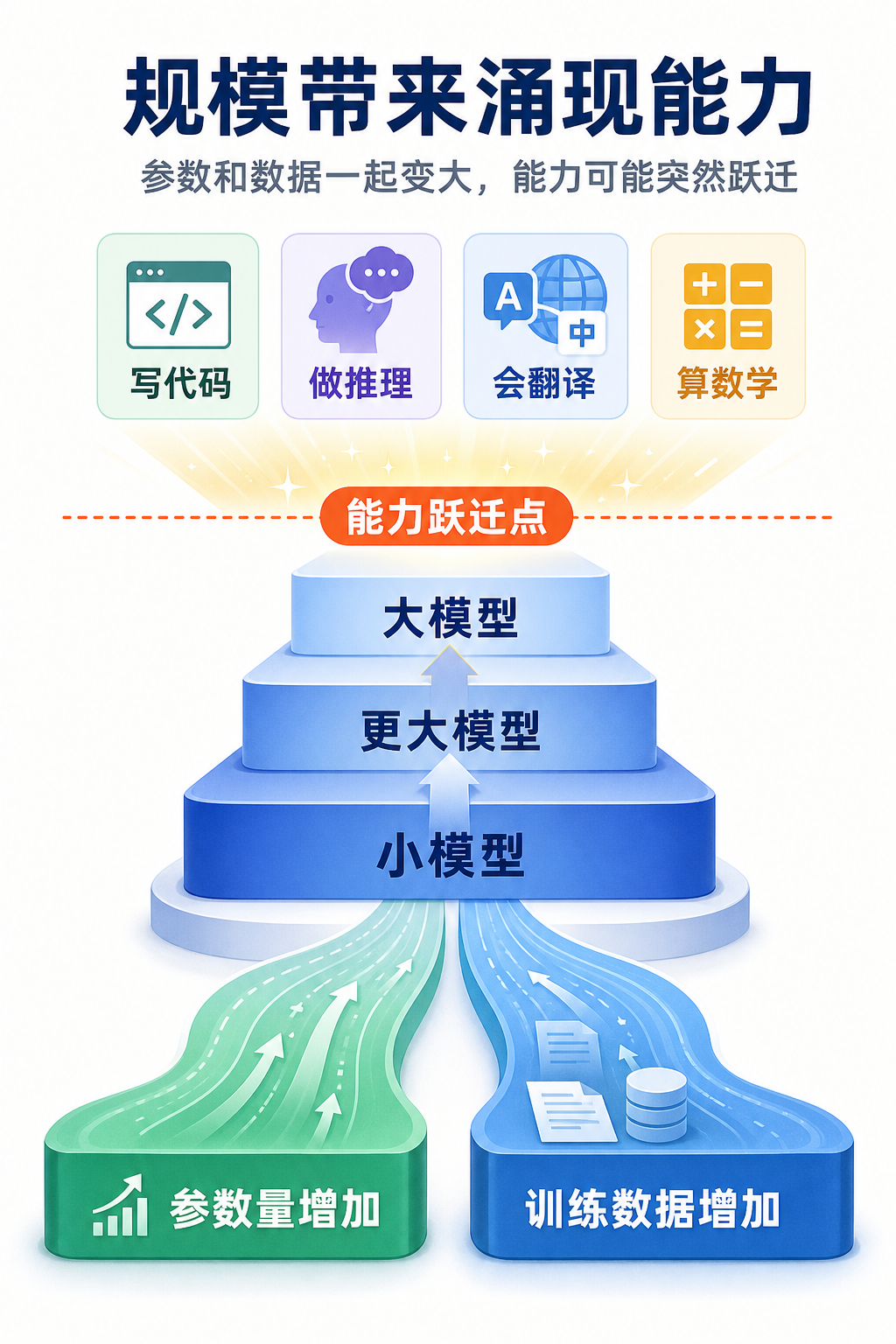
这是最让人着迷的部分。
小模型在做什么?本质上就是"接龙"——根据前面的文字,预测下一个最可能出现的词。做得好的话,它能写出语法正确、通顺连贯的句子。但也就到此为止了。
但当模型大到一定程度之后,一件奇怪的事情发生了:它突然开始会做一些训练过程中从来没有专门教过它的事情。
比如做算术题。没有人专门教它加减乘除的规则,它只是读了大量文本,其中偶尔包含数学内容,但它自己"悟"出了计算的方法。
比如写代码。训练数据里确实有大量代码,但没有人告诉它"这是一种编程语言,你需要学会它的语法和逻辑"。它从海量的代码文本中自己学会了编程。
比如逻辑推理。给它一道推理题,它能一步一步分析,得出正确答案。训练时并没有人专门教它推理的步骤。
比如跨语言翻译。它可能主要用英文训练,但它突然能用中文回答问题,甚至能在两种语言之间互译。
小模型:预测下一个词 -> 写出通顺的句子
大模型:预测下一个词 -> 做算术、写代码、推理、翻译...这种能力叫"涌现能力"。就像一个人读了足够多的书之后,突然能够举一反三,把不同领域的知识融会贯通。不是哪一本书教了他这个能力,而是知识积累到一定程度之后,量变引起了质变。
关键的一点是:这些涌现能力不是我们设计出来的。没有人知道模型参数到多少、数据到多少就会涌现出什么能力。我们只是不断把模型做得更大,然后观察它突然能做什么新事情。这种"没想到但就是出现了"的特性,是大模型最让人兴奋、也最让人不安的地方。
回顾与展望
到这里,我们在这一章走完了整个基础脉络:
第一节:语言模型是什么 -> 预测下一个词
第二节:文字变数字 -> 让计算机能处理语言
第三节:简单网络不够用 -> 语言有自己的特点,需要专门的结构
第四节:Transformer -> 注意力机制,现代大模型的基础架构
第五节:为什么要大 -> 规模带来涌现能力,量变引起质变从"语言模型就是预测下一个词"这个简单的想法出发,我们看到了文字是怎么变成数字的,为什么简单的网络处理不了语言,Transformer 是怎么用注意力机制解决这些问题的,以及为什么模型需要足够大才能展现出惊人的能力。
接下来的章节,我们会用 MiniMind 作为具体例子,看一个大模型实际是怎么工作的:推理过程是怎样的,每一步在做什么,输入一段文字之后模型内部发生了什么。有了这一章的基础,理解后面的内容会轻松很多。