Decoder Block 是什么
上一章里,我们把 Decoder Block 简单理解成“阅读和加工上下文的模块”。
这一章稍微展开一点,看看它大致做了什么。
假设输入是:
10 个 token
每个 token 是 128 维向量那么进入 Decoder Block 前,输入可以看成一个 10×128 的矩阵:
输入:10×128
[
[第 1 个 token 的向量],
[第 2 个 token 的向量],
...
[第 10 个 token 的向量]
]Decoder Block 处理后,输出通常仍然是 10×128:
输出:10×128
[
[第 1 个位置更新后的向量],
[第 2 个位置更新后的向量],
...
[第 10 个位置更新后的向量]
]也就是说:
Decoder Block:10×128 -> 10×128矩阵大小不变,但每一行的内容变了。每个位置的向量会带上更多上下文信息。
在 Decoder-only 模型里,因为不能看未来,第 i 个位置的输出向量通常只会融合第 0 到第 i 个 token 中对当前位置有用的信息。
比如输入是:
t0, t1, t2, ..., t9输出可以粗略理解成:
h0:融合 t0 的信息
h1:融合 t0, t1 的信息
h2:融合 t0, t1, t2 的信息
...
h9:融合 t0, t1, ..., t9 的信息这里的“融合”不是把前面的向量完整复制一遍,而是通过模型计算,把对当前位置有用的信息写进当前向量里。
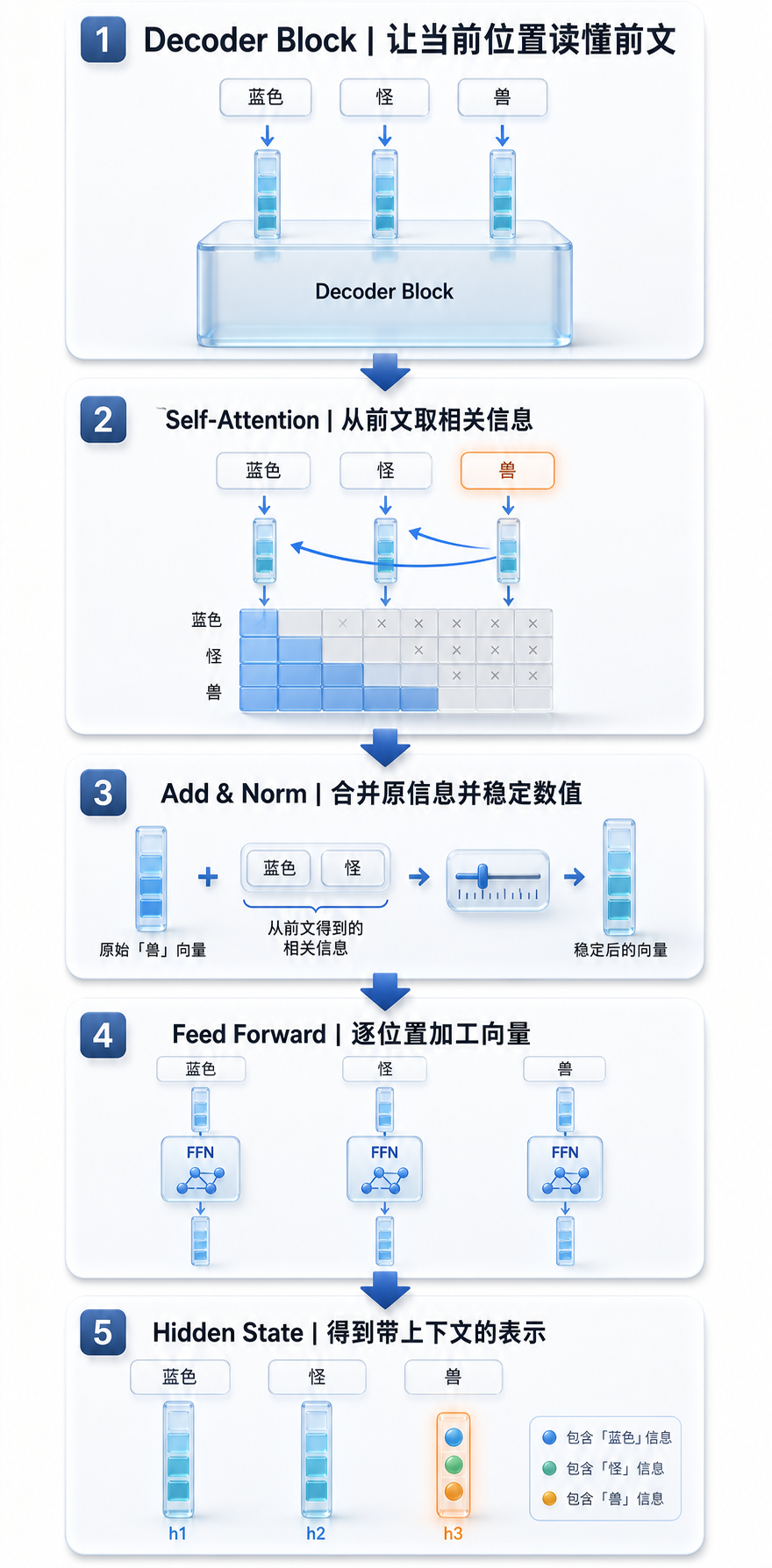
一个 Decoder Block 的大致流程
一个 Decoder Block 内部可以先粗略理解成:
输入:10×128
-> Self-Attention:每个位置参考前文
-> Add & Norm:保留原信息,并让数值更稳定
-> Feed Forward:对每个位置的向量做进一步加工
-> Add & Norm:再次保留原信息,并稳定数值
-> 输出:10×128这里先不展开公式,只先抓住每一步的作用。
用“蓝色怪兽”做一个直观例子
假设输入文本是:
蓝色怪兽为了方便说明,先假设它被 tokenizer 切成 3 个 token:
蓝色 / 怪 / 兽经过 Token Embedding 后,每个 token 会变成一个向量。这里不用真实数字,只用含义来理解:
蓝色 -> [表示“蓝色”这个 token 的向量]
怪 -> [表示“怪”这个 token 的向量]
兽 -> [表示“兽”这个 token 的向量]这时每个向量主要还是“各管各的”:
“蓝色”的向量:主要知道自己和颜色有关。
“怪”的向量:主要知道自己和怪异、怪物有关。
“兽”的向量:主要知道自己和动物、野兽有关。但模型真正需要理解的不是孤立的“蓝色”“怪”“兽”,而是它们合起来的意思:
一个蓝色的怪兽这就是 Decoder Block 要做的事:让每个位置的向量参考前文,把孤立 token 逐步加工成带上下文的向量。
在 Decoder-only 模型里,因为不能看未来,三个位置大致会这样更新:
第 1 个位置“蓝色”:
只能看“蓝色”
-> 更新后仍主要表示“蓝色”
第 2 个位置“怪”:
可以看“蓝色”和“怪”
-> 更新后不只是“怪”,还带上“蓝色的怪...”这层信息
第 3 个位置“兽”:
可以看“蓝色”“怪”“兽”
-> 更新后不只是“兽”,而是更像“蓝色怪兽”这个整体状态所以 Self-Attention 产出的新向量,可以粗略理解成:
原始“兽”的向量:
只知道自己是“兽”
Self-Attention 后给“兽”产生的新信息:
前面还有“蓝色”和“怪”,所以这里不是普通的兽,而是“蓝色怪兽”的最后一部分接着 Add 会把原来的向量和新信息加在一起:
原来的“兽”向量
+ 从上下文读到的新信息
= 更新后的“兽”位置向量它的含义可以理解成:
既保留“兽”本身的信息,
又加入“蓝色怪”这个前文带来的上下文信息。这就是为什么 Decoder Block 的输出形状还是 3×128,但内容已经变了:
输入:
[
[蓝色:较孤立的 token 向量],
[怪:较孤立的 token 向量],
[兽:较孤立的 token 向量]
]
输出:
[
[蓝色:读过上下文后的向量],
[怪:融合“蓝色 + 怪”的向量],
[兽:融合“蓝色 + 怪 + 兽”的向量]
]当模型要继续预测下一个 token 时,就会重点使用最后一个位置,也就是“兽”这个位置更新后的向量。因为它已经融合了完整的“蓝色怪兽”上下文。
Self-Attention:让每个位置参考前文
Self-Attention 可以理解成“让每个 token 去看其他相关 token”。
在 Decoder-only 模型里,它通常有一个重要限制:不能看未来。
假设当前有 10 个 token:
t1, t2, t3, ..., t10那么每个位置能看的范围大致是:
第 1 个位置:只能看 t1
第 2 个位置:可以看 t1, t2
第 3 个位置:可以看 t1, t2, t3
...
第 10 个位置:可以看 t1 到 t10这叫因果限制。它保证模型在预测下一个 token 时,不会偷看未来答案。
比如输入是:
用户:为什么天空是蓝色的?
助手:最后一个位置可以参考前面的整段问题,于是它的向量就能带上:
用户问的是天空为什么是蓝色
现在轮到助手回答
下一步应该开始解释原因这些信息不会变成中文句子,而是藏在更新后的向量里。
关于 Q/K/V、注意力分数、softmax 和因果 mask 的更多细节,可以看延伸阅读:Self-Attention 是什么。
Add & Norm:保留原信息,稳定数值
Self-Attention 会产生一组新的向量,但模型通常不会直接丢掉原来的输入。
它会做一件很朴素的事:
原来的向量 + 新加工出来的向量这叫残差连接,也就是 Add。
直观上,它的作用是:
既保留原来的 token 信息,
又加入刚刚从上下文中读到的新信息。Norm 则可以理解成“整理数值范围”。它让向量里的数字更稳定,避免一层一层计算后数值变得太乱。
所以 Add & Norm 可以粗略理解成:
把新信息加进来,同时让结果更稳定。关于 Norm 的更多细节和常见公式,可以看延伸阅读:Norm 是什么。
Feed Forward:逐位置加工向量
Self-Attention 主要负责让不同位置之间交换信息。
Feed Forward 则更像是对每个位置的向量做进一步加工。
它不会改变 token 数量,也通常不会改变最终向量维度:
输入:10×128
输出:10×128但每一行向量都会被重新处理一次。
可以把它理解成:
Self-Attention:负责读上下文。
Feed Forward:负责消化和加工每个位置读到的信息。继续用“蓝色怪兽”的例子。
Self-Attention 之后,“兽”这个位置的向量已经不只是表示“兽”,还带上了前面的“蓝色”“怪”:
“兽”位置的向量:
已经融合了“蓝色怪兽”的上下文信息。Feed Forward 接着会对这个位置的向量做进一步加工。它可以粗略理解成在问:
这里是不是一个名词短语的结尾?
它更像是在描述一个角色、动物,还是一个普通物体?
后面更可能接什么类型的内容?这些判断也不会变成中文句子,而是体现在向量里的数字变化上。
所以,“兽”这个位置经过 Feed Forward 后,可能从:
读到前文后的“兽”进一步变成:
更适合预测后续内容的“蓝色怪兽”状态如果后面要继续生成,模型可能更容易接上类似:
出现了
正在
有一双这样的 token。
可以简单记住:
Self-Attention:把前文信息读进来。
Feed Forward:把读进来的信息再加工一下,让它更适合后续预测。关于 Feed Forward 的结构、升维降维和激活函数,可以看延伸阅读:Feed Forward 是什么。
为什么要堆叠多层 Decoder Block
一个 Decoder Block 只加工一次上下文。
大语言模型通常会堆叠很多层 Decoder Block,让向量被反复更新。
可以粗略理解成:
前几层:理解局部词语和短距离关系。
中间层:整合更长范围的信息。
后面层:形成更适合预测下一个 token 的状态。这只是一个直观理解,不代表每一层一定严格分工。但总体上,多层 Decoder Block 会让模型逐步形成更丰富的上下文表示。
为什么最后一个位置能预测下一个 token
在 Decoder-only 推理中,模型每次都要预测:
当前上下文后面的下一个 token如果输入有 10 个 token,第 10 个位置可以看到前 10 个 token。
因此,经过多层 Decoder Block 后,第 10 行向量就可以理解成:
模型读完前 10 个 token 后形成的当前状态。接下来,模型会把第 10 行向量交给 LM Head:
第 10 行向量
-> LM Head
-> 整个词表上的 logits
-> 采样得到第 11 个 token所以,Decoder Block 并不是直接输出答案。它输出的是一串更新后的向量,其中最后一个位置的向量会被用来预测下一个 token。
小结
Decoder Block 的作用可以概括为:
输入一串 token 向量
-> 让每个位置参考前文
-> 保留原信息并稳定数值
-> 进一步加工每个位置的向量
-> 输出一串读过上下文后的向量如果输入是 10×128,输出通常仍然是 10×128。
变的不是矩阵大小,而是每一行向量里包含的信息。