采样一个 token
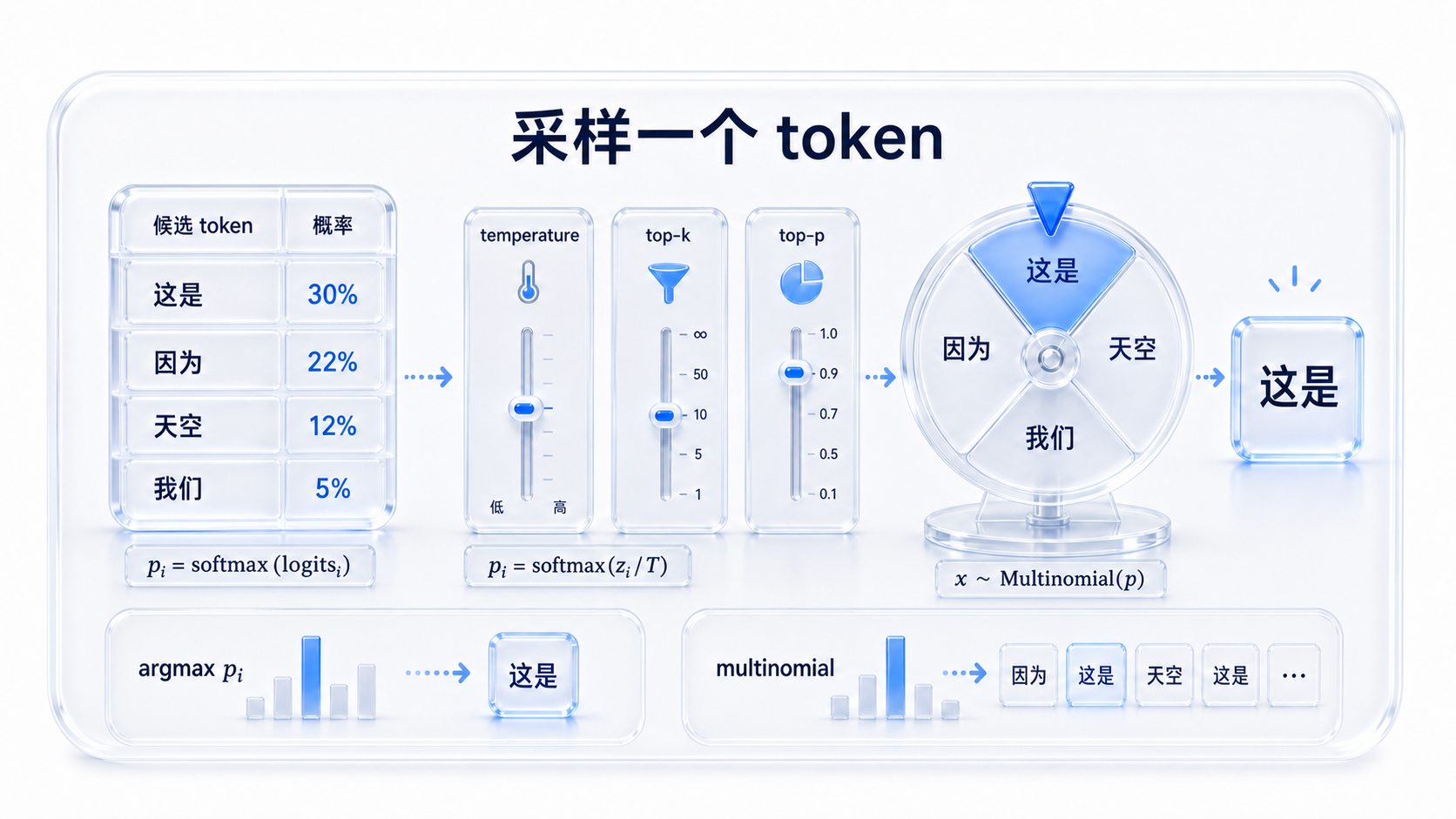
在上一阶段,模型已经根据当前上下文,给出了“下一个 token 可能是什么”的判断。
更准确地说,模型最开始输出的不是百分比,而是一组叫做 logits 的原始分数。关于 logits 的更详细解释,可以看延伸阅读:Logits 是什么。
可以把 logits 理解成模型给每个候选 token 打的分:
token logits
----------------
这是 8.2
因为 7.9
天空 6.4
我们 4.1
蓝色 3.7
... ...logits 本身还不是概率。它们只是“模型觉得哪个 token 更合适”的原始分数。一般来说,logits 越大,这个 token 越可能被选中。
为了方便采样,推理程序会把 logits 转换成概率。转换后,才会得到类似这样的候选表:
token 可能性
----------------
这是 30%
因为 22%
天空 12%
我们 5%
蓝色 3%
... ...注意,模型通常不会直接说:
下一个 token 一定是“这是”它更像是先给所有 token 打分,再把分数变成概率。采样要做的事情,就是从这张概率表里选出一个 token,作为本轮真正生成出来的内容。
为什么不总是选概率最高的 token
最直接的方法是永远选择概率最高的 token。比如上面的例子里,“这是”的概率最高,那就选“这是”。
这种方法通常叫贪心选择。它的优点是稳定、确定、容易复现;缺点是回答可能变得单调,有时也容易卡在重复或不自然的表达里。
比如模型每一步都只选最可能的 token,结果可能会很保守:
这是因为这是因为这是因为……所以很多聊天模型不会永远只选第一名,而是会在一批比较合理的候选里做选择。这样回答会更自然,也更有变化。
temperature:控制随机程度
temperature 可以理解成“随机程度”的旋钮。
temperature 低:更偏向选择高概率 token,回答更稳定
temperature 高:低概率 token 也更有机会被选中,回答更发散比如模型原本认为:
这是 30%
因为 22%
天空 12%如果 temperature 很低,“这是”会更容易被选中。
如果 temperature 较高,“因为”“天空”等候选也会更有机会被选中。
可以粗略理解为:
低温:稳一点
高温:放开一点温度不是越高越好。太低可能死板,太高可能胡乱发挥。
top-k:只看前 k 个候选
top-k 的思路很简单:只保留概率最高的 k 个 token,其他候选直接丢掉。
比如 top_k = 3,候选表是:
这是 30%
因为 22%
天空 12%
我们 5%
蓝色 3%
... ...那么只保留前三个:
这是
因为
天空然后再从这几个候选里选择一个。
这样做可以避免模型选到特别离谱的低概率 token。
top-p:只看累计概率足够高的一组候选
top-p 也叫 nucleus sampling。它不是固定保留前几个 token,而是从高到低排序后,保留一组“累计概率达到 p”的候选。
比如 top_p = 0.9,意思是:
从最可能的 token 开始往后加,
直到这些候选的总概率接近 90%,
然后只在这组候选里采样。它比 top-k 更灵活。
如果模型很确定,下一个 token 只有少数几个合理选项,top-p 保留下来的候选就少。
如果模型不太确定,有很多说法都合理,top-p 保留下来的候选就会多一些。
采样策略:从概率分布里抽一个 token
经过 temperature、top-k、top-p 这些处理后,剩下的候选 token 会重新形成一个概率分布。
这时有两种常见选择方式:
贪心选择:直接选概率最高的 token
随机采样:按概率大小随机抽一个 token随机采样里很常见的一种方法叫 multinomial sampling,也就是多项分布采样。
它的意思是:每个 token 被选中的机会,和它当前的概率成正比。
比如候选表是:
token probability
---------------------
这是 50%
因为 30%
天空 20%multinomial 采样不是永远选“这是”,而是大致按照下面的机会抽取:
抽到“这是”的概率约 50%
抽到“因为”的概率约 30%
抽到“天空”的概率约 20%所以同一个问题,在相同参数下多跑几次,也可能生成不同回答。概率高的 token 更容易出现,但低概率 token 只要还在候选范围里,也有机会被抽中。
如果不想要随机性,也可以关闭采样,直接使用 argmax:
argmax:选择概率最高的 token
multinomial:按照概率分布随机抽一个 tokenMiniMind 的推理实现里,do_sample=True 时使用 multinomial 采样;如果关闭采样,则使用 argmax 选择最高分 token。
重复惩罚:减少一直说同样内容
生成文本时,模型有时会重复前面已经说过的词。比如:
这是因为因为因为因为……重复惩罚会降低已经出现过的 token 再次被选中的机会,让模型更愿意继续往前说。
它不是完全禁止重复,因为有些重复是正常的,比如“非常非常好”。它只是减少无意义重复的概率。
更具体一点,重复惩罚通常会在采样前修改 logits。
比如某个 token 已经在前文出现过,并且它这一步的 logit 仍然很高:
token 原始 logit
--------------------
因为 8.0如果设置了 repetition_penalty = 1.2,那么这个已经出现过的 token 会被压低:
因为的新 logit ≈ 8.0 / 1.2 = 6.67这样一来,它后面经过 softmax 转成概率时,概率就会下降。
如果某个出现过的 token 原本 logit 是负数,一些实现会反过来把它乘以惩罚系数,让它变得更负:
原始 logit:-2.0
惩罚后: -2.0 * 1.2 = -2.4这样做的目的也是一样的:让已经出现过的 token 更不容易再次被选中。
可以把重复惩罚理解成:
这个 token 已经说过了
-> 降低它再次出现的分数
-> 但不完全禁止它出现MiniMind 的实现也是这个思路:如果某个 token 已经出现在当前上下文里,就根据 repetition_penalty 调整它的 logit,然后再继续做 top-k、top-p 和 multinomial 采样。
一个完整的采样顺序
把这些步骤串起来,一轮 token 采样大致是:
模型输出 logits
-> 用 temperature 调整 logits
-> 对已经出现过的 token 做重复惩罚
-> 用 top-k 过滤低排名候选
-> 用 top-p 保留累计概率合适的候选集合
-> softmax 得到概率分布
-> 用 multinomial 采样抽出一个 token如果关闭随机采样,最后一步会变成:
-> 用 argmax 选择概率最高的 token采样完成后发生什么
假设这一步最终选中了:
这是那么它就会被接到原来的上下文后面:
用户:为什么天空是蓝色的?
助手:这是接下来,模型会基于这个新的上下文继续预测下一个 token。
也就是说,采样不是只发生一次,而是在生成回答的过程中反复发生:
预测候选 token
-> 采样一个 token
-> 拼回上下文
-> 再预测下一个 token
-> 再采样
-> ...什么时候停止采样
模型会一直重复“预测 -> 采样 -> 拼接”的过程,直到出现停止条件。
常见停止条件有两个:
生成了结束符
达到了最大生成长度结束符是一个特殊 token,用来表示“回答到这里可以结束了”。如果模型一直没有生成结束符,推理程序也会用最大生成长度兜底,避免无限生成。
小结
token 采样就是从模型给出的候选 token 概率里,选出本轮真正要生成的 token。
可以把它理解成:
模型给出候选表
-> 用 temperature 调整随机程度
-> 用 top-k / top-p 去掉不太合理的候选
-> 必要时降低重复 token 的机会
-> 用 multinomial 按概率抽出一个 token
-> 接回上下文所以,大模型的回答既不是完全固定的,也不是完全随机的。它是在“模型认为合理的范围内”,根据采样策略一步一步生成出来的。