预训练:让模型学会语言
前面我们完整走了一遍推理流程——模型拿到用户的输入,经过 tokenizer 切分、embedding 编码、多层 Transformer 处理、LM Head 打分,最后采样生成下一个 token,循环往复直到输出完整回答。但这一切有一个前提:模型得先经过训练。一个随机初始化的模型,给它输入"你好",它吐出来的只会是乱码。
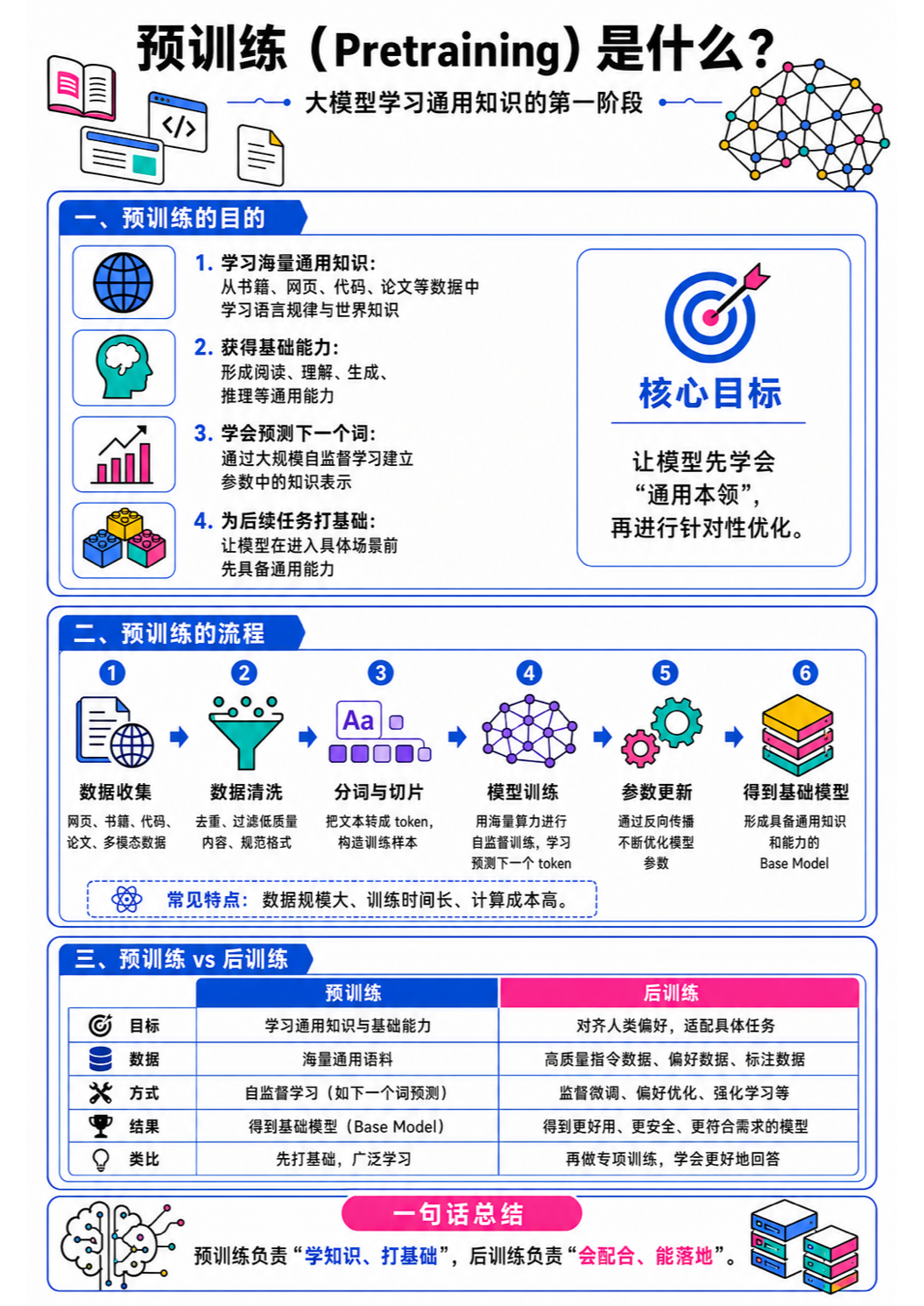
模型的训练通常分为多个阶段,而预训练是第一个、也是最基础的阶段。它决定了模型能不能"说人话",是后面所有能力的地基。
预训练的目标:广泛阅读
预训练就像让一个人大量阅读——不是读某一本教材,而是读互联网上能找到的几乎所有文字:网页、书籍、论文、代码、百科、论坛帖子……模型在这些海量文本上反复学习,掌握语言的统计规律。
拿 GPT-3 来说,它的训练数据包含了几千亿个 token,涵盖了几十种语言、数十个领域。想象一下,如果一个人能把互联网上大部分的文字都读一遍,他对语言的理解会达到什么程度。
关键的一点:预训练不是在教模型"回答问题"。它只是在让模型学会"语言的模式"——什么样的词后面通常接什么词,什么样的句子结构是通顺的,什么样的知识是事实。模型在预训练阶段从来没见过"用户问、助手答"这种格式,它只是在一遍遍阅读纯文本。
打个比方,预训练就像一个人从小到大读了无数书,积累了庞大的知识储备和语言能力,但没有人专门教他怎么跟人对话、怎么回答问题。他只是"什么都看过",所以当你问他问题时,他能接得上话——但回答得可能不太得体,因为他从没练过"对话"这门课。
自回归语言建模:训练视角下的"预测下一个词"
读者在推理章节已经见过 token 预测:模型拿到一段上下文,预测下一个 token 是什么。推理时,我们只关心最后一个位置的预测——模型根据已有内容,猜出紧接着的那个 token。
训练时做的事情本质相同,但规模不同:每个位置都在学习预测下一个 token。
来看一个具体例子。假设训练数据中有这样一句话:
今天 天气 真 不错推理时,模型看到"今天 天气 真",预测"不错"——只关心最后一步。
训练时,模型要同时学习四组预测:
位置 1:看到 [今天] -> 预测 天气
位置 2:看到 [今天, 天气] -> 预测 真
位置 3:看到 [今天, 天气, 真] -> 预测 不错
位置 4:看到 [今天, 天气, 真, 不错] -> 预测 <结束>一句话就能产生多个训练样本。模型在每个位置都做出预测,然后和真实答案对比,算出损失,通过反向传播更新参数。这正是第 00 章讲过的训练闭环——预测、算损失、反向传播、梯度下降——只不过现在应用在语言的 token 序列上。
可以想象,训练时模型一次处理的是一整段文本(通常几千个 token),每个位置都产生一个预测、一个损失。最终把这些位置的损失加在一起,做一次反向传播,更新参数。所以训练的效率其实很高——不是一句话一句话地学,而是一大片一大片地学。
这种"根据前面的内容预测下一个 token"的训练方式,叫做自回归语言建模(Autoregressive Language Modeling)。GPT 系列的所有模型都是这样训练的,这也是"GPT"里"G"(Generative,生成式)和"P"(Pre-trained,预训练)的由来。
为什么预测下一个词就能学会语言
乍一听,"预测下一个词"好像只是个文字接龙游戏。但仔细想想:要做到准确预测,模型必须理解很多东西。
比如这句话:
法国的首都是____要预测出"巴黎",模型得知道法国是一个国家,国家有首都,法国的首都是巴黎——这是事实知识。
再看这个:
如果明天下雨,我们就____要预测出合理的内容,模型得理解条件句的语法结构,知道"下雨"和"不出门"之间的因果关系——这是语法和推理。
还有更微妙的:
他气得____后面可能接"摔门而去""说不出话""脸都红了"。要选出一个通顺的,模型得理解"气"的情绪色彩,以及中文里描写愤怒的常见搭配——这是语感和文化。
换句话说,要想准确预测下一个词,模型被迫学会了语法、事实、推理、甚至一定程度的世界知识。这就是为什么预训练有效——压缩即理解。模型把海量文本中的规律压缩进了参数里,而这些规律恰好构成了"理解语言"所需的能力。
当然,预训练学到的能力也有局限。模型学到的是文本中的统计规律,而不是真正的"思考"。它可能知道"2 + 2 = 4"后面经常跟着"因为 2 加 2 等于 4",但这不意味着它真的理解了数学运算。这种统计学习和真正理解之间的差距,正是后续微调阶段要弥补的。
预训练、微调、推理的关系
在深入预训练的细节之前,先建立一个全局视角。一个语言模型从诞生到被使用,大致经历三个阶段:
预训练:在海量文本上学习语言的基础能力(本篇主题)
↓
微调:在特定任务或对话数据上学习如何回答问题、听从指令
↓
推理:训练完成后,接收用户输入,生成回答(上一章已讲)用一个类比来总结:
- 预训练 = 一个人从小大量阅读,积累了广博的知识和语言能力,但不太会跟人对话
- 微调 = 这个人参加了"沟通技巧培训班",学会了怎么组织回答、听从指令
- 推理 = 这个人正式上岗,开始回答你的问题
本篇聚焦预训练,微调的细节会在后续章节展开。
值得一提的是,预训练和微调的训练方式其实是一样的——都是自回归语言建模,都在学习预测下一个 token。区别只在于数据不同:预训练用的是海量通用文本,微调用的是精心准备的对话和指令数据。所以理解了预训练,微调的原理也就懂了大半。
预训练全流程预览
预训练不是一步完成的,而是一个完整的流水线。先看全局:
┌─────────────────────────────────────────────────────┐
│ 预训练全流程 │
│ │
│ 数据准备 │
│ (收集语料 → 清洗过滤 → 分词编码) │
│ ↓ │
│ 模型初始化 │
│ (随机初始化所有参数) │
│ ↓ │
│ 训练循环 ←←←←←←←←←←←←←←←←←← │
│ (前向传播 → 计算损失 → 反向传播 → 更新参数) │
│ ↓ ↑ │
│ 保存检查点 ↑(反复迭代数十万步) │
│ (定期保存模型快照) ↑ │
│ ↓ ↑ │
│ 最终模型 ←←←←←←←←←←←←←←←←← │
│ │
└─────────────────────────────────────────────────────┘每个环节的职责如下:
数据准备:收集大量文本,清洗掉低质量内容,分词成 token 序列。数据的质量和数量直接决定模型能力的上限——"垃圾进,垃圾出"在预训练里体现得淋漓尽致。这部分细节很多,下一篇会专门讲。
模型初始化:创建一个 Transformer 模型,把所有参数设为随机值。此时的模型什么都不知道,给它任何输入,输出都是随机的。模型的大小(参数量)在这个阶段就确定了,后面不会再改变。
训练循环:这是预训练的核心,也是耗时最长的环节。模型反复做"前向传播(预测下一个 token) → 计算损失 → 反向传播 → 更新参数"这个循环。每一步参数都在微调,模型的预测也在一点点变准。这个循环通常会跑几十万甚至上百万步,训练过程中我们会观察损失是否在持续下降,以此判断训练是否正常。
保存检查点:训练过程中定期保存模型的参数快照,方便出问题时回退,也方便后续挑选表现最好的版本。训练完的模型就可以进入微调阶段了。
这个流程看起来不复杂,但每个环节都有大量工程细节。后续几篇会逐一展开:数据怎么准备、训练循环怎么实现、模型怎么初始化、训练过程中要关注什么。
小结
预训练的核心思想其实很简单:给模型看海量文本,让它学习预测下一个 token。通过这个过程,模型被迫学会了语法、事实和推理能力——这就是自回归语言建模的力量。
我们把这一章的关键内容总结一下:
预训练的目标:让模型学会语言的统计规律
训练方式:自回归语言建模——每个位置都预测下一个 token
为什么有效:压缩即理解——预测下一个词需要语法、事实、推理
训练流程:数据准备 → 模型初始化 → 训练循环 → 保存检查点但"简单"不等于"容易"。预训练是整个流程中计算量最大的阶段——一个现代大模型的预训练可能需要数千块 GPU 跑上几个月,消耗的计算资源可能价值数百万美元。下一篇我们就从第一步开始:模型要从什么数据中学习?数据准备都有哪些讲究?