数据准备:模型从什么数据中学习
上一篇看到了预训练的全流程:数据准备 → 模型初始化 → 训练循环 → 保存检查点。整个过程像一条流水线,而数据准备就是这条流水线的第一个环节——也是决定最终效果上限的环节。模型要从海量文本中学习语言规律,那这些文本是什么样子的?又是怎么变成模型能吃的"训练样本"的?这一篇我们就来看这些问题。
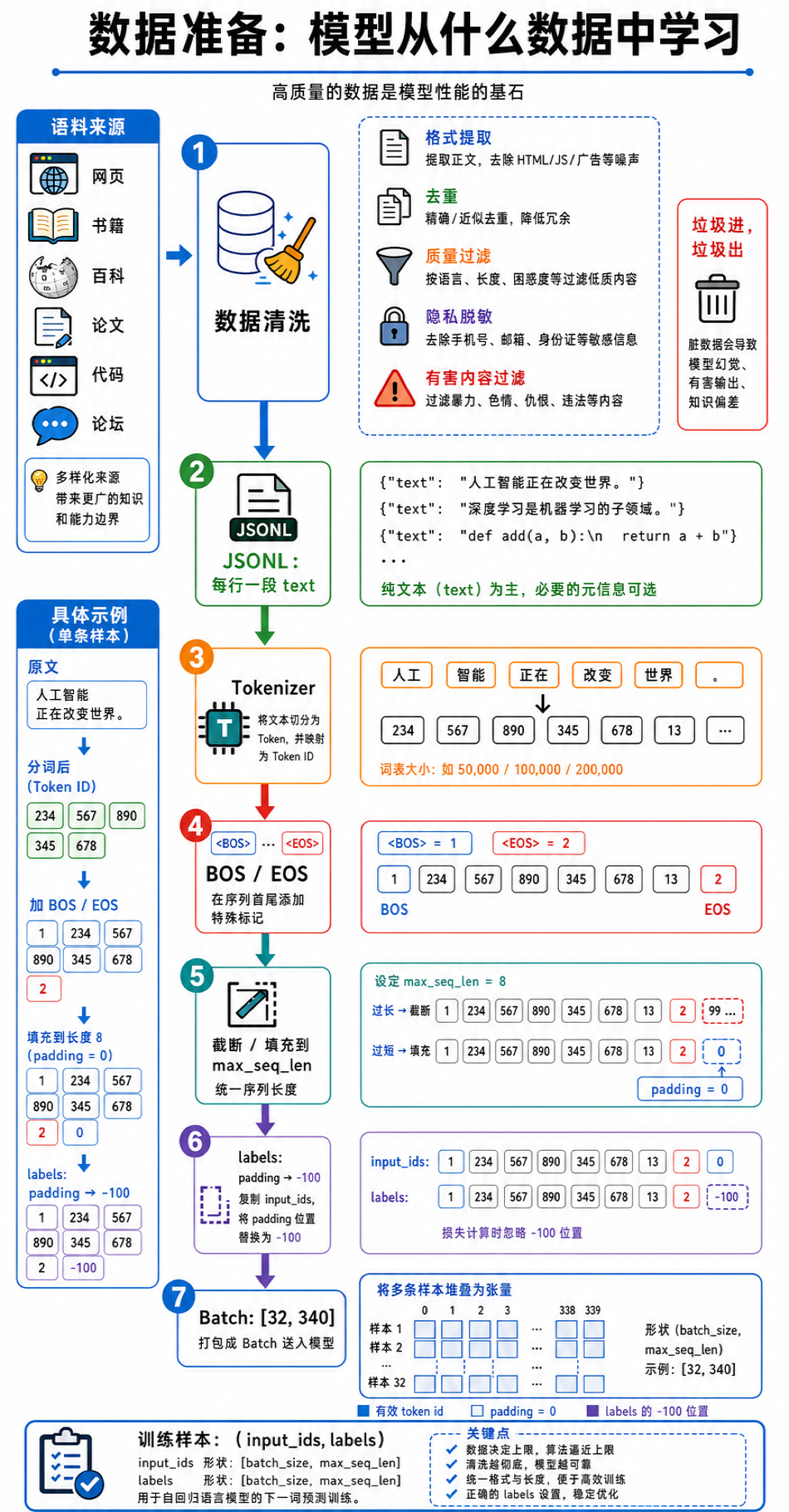
语料来源:模型读什么
预训练需要大量文本——不是几本书、几个网页,而是整个互联网规模的文本。常见的语料来源有这些:
- 网页文本:互联网上爬取的网页内容,量最大、覆盖面最广,但噪声也最多。一个大型语料库可能包含数十亿个网页。
- 书籍:电子书、扫描识别的纸质书。书籍的语言质量通常比网页高得多,而且涵盖长篇连贯的论述,对模型学习逻辑推理很有帮助。
- 百科:维基百科、百度百科这类结构化的知识库。信息密度高,事实准确,是模型学习"知识"的重要来源。
- 论文:学术论文,覆盖数学、物理、计算机等各个学科。让模型接触到严谨的学术表达和专业术语。
- 代码:GitHub 等代码托管平台上的开源代码。代码有严格的语法规则和逻辑结构,对模型的推理能力提升很大。
- 论坛和社交媒体:问答、讨论、评论等。语言风格多样,更接近日常对话。
这些不同来源的文本混在一起,构成预训练语料。数据量通常以token 数来衡量——大型模型的训练数据可能有几千亿甚至上万亿个 token。这么多的文本,不可能手动整理,所以预训练语料几乎都是从网上自动收集的。
MiniMind 的语料格式
MiniMind 作为一个小型教学项目,数据量自然没法和大型模型比,但格式是一样的。MiniMind 使用 JSONL 格式存储预训练数据,每一行是一个 JSON 对象,只有一个字段 text:
{"text": "今天天气很好,适合出门散步。"}
{"text": "Python 是一门流行的编程语言,以其简洁的语法著称。"}
{"text": "人工智能技术在近年来取得了飞速发展,深刻改变了人们的生活方式。"}就这么简单——每条数据就是一段纯文本,没有标签,没有分类,没有问答对。预训练数据的核心特点就是:大量纯文本,覆盖面广。模型要做的不是学某一种任务,而是从这些文本中普遍地学会语言规律。
数据清洗:垃圾进,垃圾出
从网上爬下来的原始数据是很脏的。如果你打开一个原始网页的 HTML 源码,会看到大量的标签、脚本、样式代码,真正有价值的文本内容淹没在里面。而且就算把文本提取出来了,里面还有各种问题。
常见的噪声包括:
- 格式噪声:HTML 标签、CSS 代码、JavaScript 脚本、Markdown 标记、导航栏文字、页脚广告
- 内容噪声:重复的段落、机器生成的垃圾文本、乱码、拼写错误
- 隐私信息:手机号、身份证号、邮箱地址、家庭住址
- 有害内容:暴力、歧视、虚假信息
如果不做清洗,直接把原始数据喂给模型,模型就会学到一堆乱七八糟的东西——毕竟模型是靠统计规律学习的,你给它什么,它就学什么。
数据清洗通常包括这些步骤:
- 格式提取:从 HTML 等原始格式中提取纯文本,去掉所有标签和代码
- 去重:删除重复或高度相似的文本。互联网上有大量复制粘贴的内容,不去重的话模型会在重复内容上浪费学习时间
- 质量过滤:用规则或小模型过滤掉低质量内容。比如文本太短、包含太多特殊字符、语言混杂等
- 隐私脱敏:用正则表达式或命名实体识别去掉个人隐私信息
- 有害内容过滤:过滤掉包含暴力、歧视等有害内容的文本
"垃圾进,垃圾出"这句话在预训练里体现得淋漓尽致。数据质量直接决定模型能力的上限——模型架构再先进,如果喂给它的是垃圾数据,学出来的也只能是垃圾。这也是为什么各大公司花大量精力在数据清洗上——在某些情况下,更好的数据比更大的模型更有效。
从文本到训练样本
数据清洗完之后,我们有了大量干净的文本。但模型不能直接读文本——它只认识数字。所以还需要一个转换过程,把每段文本变成模型能处理的训练样本。
读者在 tokenize 章节 已经了解了 BPE 分词的原理,知道 tokenizer 怎么把文本切成 token id 序列。这里我们聚焦预训练场景下的特殊处理——除了分词,还要加特殊标记、统一长度、构建标签。
用一个具体的例子走完整个流程。假设我们有一条文本:
今天天气很好,适合出门散步。MiniMind 的 max_seq_len 设为 340,但为了演示方便,我们假设 max_seq_len = 8。
步骤一:分词
tokenizer 把文本切成 token id 序列。读者已经知道,分词的结果取决于 tokenizer 的词表和分词算法。这里假设分词结果是:
"今天天气很好,适合出门散步。" → [234, 567, 890, 345, 678]这一步就是纯粹的文本到数字的转换,和推理时做的分词一模一样。唯一的不同是,预训练时我们设置了 add_special_tokens=False,表示不自动加特殊标记——因为我们想手动控制标记的位置。
步骤二:加特殊标记
在 token 序列的开头加 BOS(Begin Of Sentence),结尾加 EOS(End Of Sentence):
分词结果: [234, 567, 890, 345, 678]
加特殊标记:[1, 234, 567, 890, 345, 678, 2]
^ ^
BOS (id=1) EOS (id=2)为什么需要这两个标记?
BOS 告诉模型"一段文本从这里开始"。模型看到 BOS token,就知道接下来要开始处理新的输入了。在训练中,BOS 后面的第一个 token 就是模型要学习的第一个预测目标。
EOS 告诉模型"这段文本到这里结束"。模型需要学会在合适的时候生成 EOS,表示"我说完了"。如果没有 EOS,模型在推理时就会一直生成下去,不知道什么时候停。
这两个标记就像文章的开头和句号——虽然没有它们文本也读得懂,但有了它们,结构更清晰,模型处理起来也更规范。
步骤三:截断或填充,统一长度
现在 token 序列有 7 个元素:[1, 234, 567, 890, 345, 678, 2],而 max_seq_len = 8,还差一个。怎么办?用 padding token(通常是 id=0)填满:
填充后:[1, 234, 567, 890, 345, 678, 2, 0]
^
padding (id=0)为什么要统一长度?因为 GPU 的并行计算要求同一个 batch 内所有样本长度一致。你可以理解成 GPU 是一批一批处理数据的,每批数据像一张表格——所有行(样本)的列数(长度)必须相同,GPU 才能高效地做矩阵运算。如果不统一长度,有的样本长有的样本短,GPU 就没法把它们整齐地排在一起。
实际训练中会碰到两种情况:
- 文本太长:如果分词后的 token 数超过了
max_seq_len,就直接截断,只保留前面max_seq_len - 2个 token(留位置给 BOS 和 EOS)。被截掉的部分就丢弃了。这也是为什么max_seq_len不能设太小——太短的话,长文本会被大量截断,模型学不到完整的内容。 - 文本太短:如果 token 数不够
max_seq_len,就用 padding token 填满剩余位置。MiniMind 的max_seq_len = 340,但实际文本可能只有十几个 token,这时候就有大量的 padding。这是正常的,不用担心浪费——后面会看到,padding 位置不会参与损失计算。
步骤四:构建 labels
labels 就是 input_ids 的一份副本,把 padding 位置改成 -100。
input_ids: [1, 234, 567, 890, 345, 678, 2, 0]
labels: [1, 234, 567, 890, 345, 678, 2, -100]
唯一的区别 ↑为什么要把 padding 改成 -100?因为 padding 不是真正的文本,模型不应该在 padding 位置上学习。PyTorch 的交叉熵损失函数有一个约定:看到 -100 就跳过,不计算损失。所以 padding 位置被标记为 -100 后,损失函数只会关注真正的文本内容。
这里有一个容易混淆的问题:为什么不直接在 input_ids 里用 -100 做 padding?因为 input_ids 是给模型看的——模型会把每个位置的 id 查表变成 embedding 向量。-100 不是一个有效的 token id,模型没法用它查表。所以 input_ids 用 0(一个正常的 token)做 padding 让模型正常计算,labels 用 -100 告诉损失函数跳过这些位置。两者职责不同,填充值不同。
经过四个步骤,一段文本变成了两个等长的序列:
原始文本: "今天天气很好,适合出门散步。"
↓ 分词
[234, 567, 890, 345, 678]
↓ 加 BOS/EOS
[1, 234, 567, 890, 345, 678, 2]
↓ 填充到 max_seq_len
input_ids: [1, 234, 567, 890, 345, 678, 2, 0]
↓ 复制并把 padding 改为 -100
labels: [1, 234, 567, 890, 345, 678, 2, -100]这一对 (input_ids, labels) 就是一个训练样本。
批次构建:打包处理
单个训练样本准备好了,但模型不是一个一个处理的,而是一批一批处理的。把多个样本打包在一起,就叫一个批次(batch)。
为什么需要 batch?因为 GPU 擅长并行计算。GPU 的设计理念是:与其把一件事做得很快,不如同时做很多件事。一个一个地处理样本,GPU 的大部分计算单元都在闲置,非常浪费。把多个样本打包成 batch 一起送进去,GPU 就可以同时处理它们,效率大幅提升。
MiniMind 的 batch_size = 32,意味着每次同时处理 32 个样本。每个样本的形状是 [max_seq_len](即 [340]),32 个样本堆叠在一起,就形成了一个形状为 [32, 340] 的张量:
batch 的形状:[batch_size, max_seq_len] = [32, 340]
┌─────────────────────────────────────────────┐
│ 样本 1: [1, 234, 567, ..., 2, 0, 0, 0, 0] │ ← input_ids,长度 340
│ 样本 2: [1, 89, 456, ..., 68, 2, 0, 0, 0] │
│ 样本 3: [1, 123, 456, ..., 789, 2, -1, 0] │
│ ... │
│ 样本 32: [1, 567, 890, ..., 345, 2, 0, 0] │
└─────────────────────────────────────────────┘同样,labels 也是一个 [32, 340] 的张量,和 input_ids 一一对应。
这就是为什么前面说需要统一长度——如果样本长短不一,就没法整齐地堆叠成一个矩阵。padding 的存在就是为了填平这种差异,而 labels 中的 -100 则确保 padding 位置不影响训练。
代码参考
来看看 MiniMind 的 PretrainDataset 是怎么实现上述流程的(文件:external/minimind/dataset/lm_dataset.py):
class PretrainDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length=512):
super().__init__()
self.tokenizer = tokenizer
self.max_length = max_length
# 从 JSONL 文件加载数据,每行是一个 {"text": "..."} 的 JSON 对象
self.samples = load_dataset('json', data_files=data_path, split='train')
def __getitem__(self, index):
sample = self.samples[index]
# 步骤一:分词,截断到 max_length - 2(留位置给 BOS 和 EOS)
tokens = self.tokenizer(
str(sample['text']),
add_special_tokens=False,
max_length=self.max_length - 2,
truncation=True
).input_ids
# 步骤二:在开头加 BOS,结尾加 EOS
tokens = [self.tokenizer.bos_token_id] + tokens + [self.tokenizer.eos_token_id]
# 步骤三:不足 max_length 的位置用 padding token 填充
input_ids = tokens + [self.tokenizer.pad_token_id] * (self.max_length - len(tokens))
input_ids = torch.tensor(input_ids, dtype=torch.long)
# 步骤四:labels = input_ids 的副本,padding 位置设为 -100
labels = input_ids.clone()
labels[input_ids == self.tokenizer.pad_token_id] = -100
return input_ids, labels代码非常简洁,四个步骤一目了然:
- 分词(第 10-15 行):调用 tokenizer 把文本转成 token id,
add_special_tokens=False不自动加标记,truncation=True超长则截断,max_length=self.max_length - 2留两个位置给 BOS 和 EOS - 加特殊标记(第 17 行):手动在开头加
bos_token_id(值为 1),结尾加eos_token_id(值为 2) - 填充(第 19 行):用
pad_token_id(值为 0)填充到max_length,然后转成 PyTorch 张量 - 构建 labels(第 21-22 行):复制
input_ids,把 padding 位置(值为 0)替换为 -100
返回的 (input_ids, labels) 就是前文说的训练样本。DataLoader 会自动把多个样本打包成 batch,形状为 [batch_size, max_seq_len],也就是 [32, 340]。
小结
数据准备的完整流程可以概括为一条流水线:
原始文本(JSONL 格式,每行一段纯文本)
↓ 数据清洗(去重、过滤、脱敏)
↓ 分词(tokenizer 切成 token id 序列)
↓ 加特殊标记(BOS 在开头,EOS 在结尾)
↓ 截断或填充(统一到 max_seq_len)
↓ 构建 labels(padding 位置设为 -100)
↓ 打包成 batch(形状:[batch_size, max_seq_len])
↓
训练样本就绪:每个 batch 是一对 (input_ids, labels)几个关键点回顾:
- 语料:大量纯文本,覆盖面广,以 JSONL 格式存储
- 清洗:"垃圾进,垃圾出",数据质量决定模型能力上限
- 特殊标记:BOS 标记文本开始,EOS 标记文本结束
- padding 与 -100:padding 让所有样本长度统一,-100 让损失函数跳过 padding 位置
- batch:多个样本打包在一起,充分利用 GPU 的并行计算能力
现在数据准备好了,每个训练样本是一对 (input_ids, labels)。下一篇我们进入训练循环,看看模型怎么用这些数据来更新自己的参数——从随机初始化到学会"说人话",这个过程是怎么发生的。