训练循环:模型怎么从数据中学习
上一篇讲完了数据准备,现在每个训练样本是一对 (input_ids, labels),形状分别是 [340](一个样本)或 [32, 340](一个 batch)。数据已经就位,接下来就是训练循环的核心问题了:模型怎么用这些数据来更新自己的参数?
这一篇我们走进训练循环,看模型从随机初始化到学会"说人话"的过程是怎么一步步发生的。
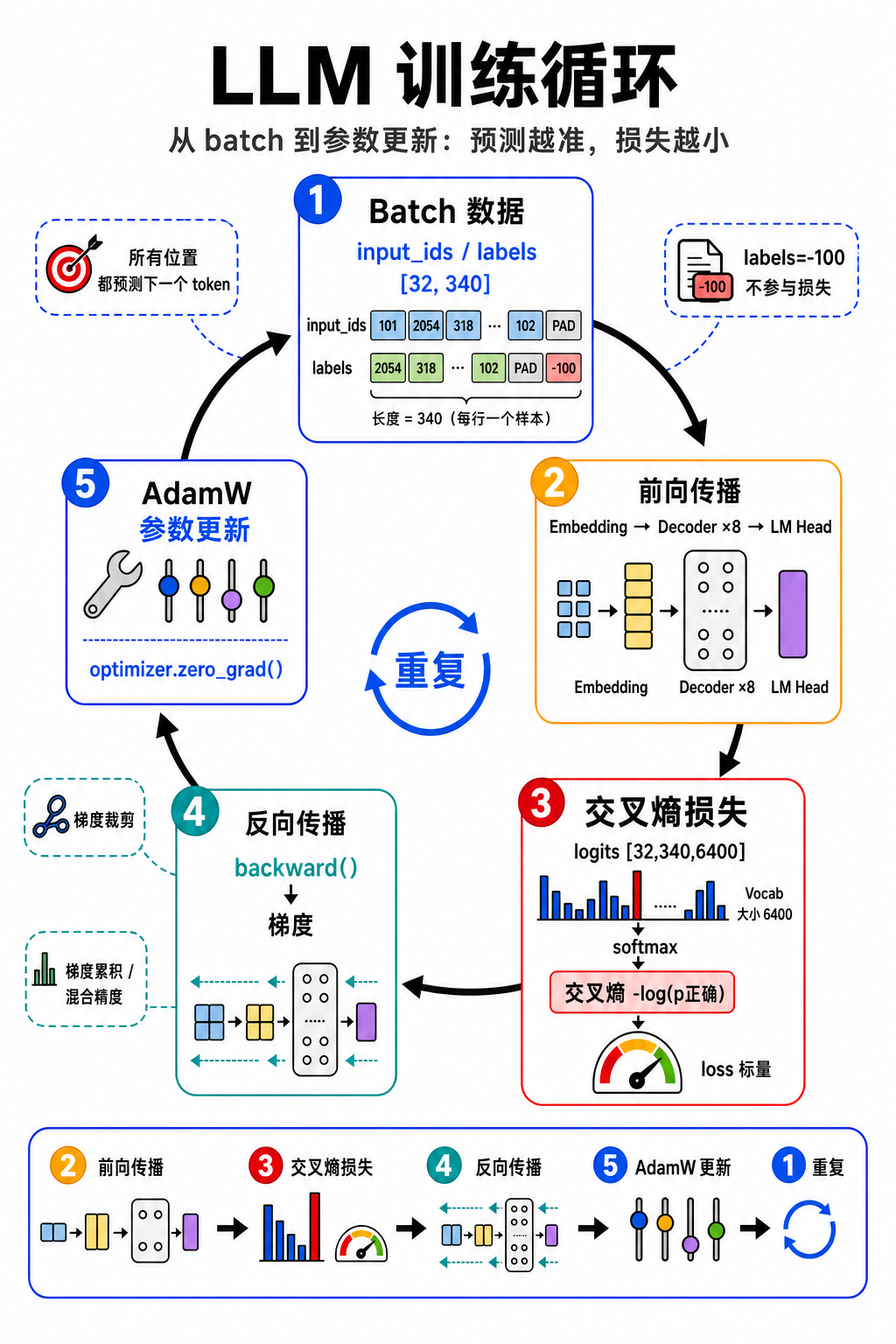
训练循环的全貌
训练循环做的事,本质上和你在 00 章节中学过的训练闭环一样:拿数据算损失,算梯度,更新参数,重复。只不过现在我们把那个通用框架套到了 LLM 的具体场景中。一个训练 step 的完整流程是这样的:
┌─────────────────────────────────────────────────────┐
│ 一个训练 step │
│ │
│ 1. 取一个 batch 的 (input_ids, labels) │
│ ↓ │
│ 2. 前向传播:input_ids 经过模型,输出 logits │
│ ↓ │
│ 3. 计算损失:logits 和 labels 对比,算交叉熵 │
│ ↓ │
│ 4. 反向传播:从损失出发,算出每个参数的梯度 │
│ ↓ │
│ 5. 参数更新:优化器根据梯度调整参数 │
│ ↓ │
│ 回到第 1 步,取下一个 batch,重复 │
└─────────────────────────────────────────────────────┘整个训练过程就是把这个循环跑成千上万次。每跑一次,模型的参数就往"预测更准"的方向挪一小步。几百万步下来,原本随机输出的模型就慢慢学会了语言的规律。
接下来我们逐步拆解这五步。前向传播和推理时的流程基本一致(只是多了一些细节),而损失函数是这一篇的重点——它决定了模型"往哪个方向学"。
前向传播
前向传播读者已经不陌生了。在推理章节中,我们走过一遍完整流程:token id 经过 Embedding 变成向量,再经过多层 Decoder Block 做上下文融合,最后通过 LM Head 输出 logits。
训练时的前向传播和推理几乎一样,只有一个关键区别:推理时只看最后一个位置的 logits,训练时所有位置的 logits 都有意义。
为什么?因为训练时模型的输入是一整段文本,每个位置都在做"预测下一个 token"这件事。比如输入 "<s> 今天 天气 很 好",模型在这五个位置上分别输出一组 logits,每个位置都在预测它后面的那个 token。
具体的形状变化:
输入 input_ids: [batch_size, seq_len]
= [32, 340]
↓ Embedding 层
嵌入向量: [batch_size, seq_len, hidden_size]
= [32, 340, 768]
↓ 8 层 Decoder Block
上下文表示: [batch_size, seq_len, hidden_size]
= [32, 340, 768]
↓ LM Head(线性层)
logits: [batch_size, seq_len, vocab_size]
= [32, 340, 6400]logits 的含义是:对于序列中的每个位置,模型给词表中 6400 个 token 各打了一个分数。分数越高,模型认为那个 token 越可能出现在下一个位置。
这 6400 个分数就是原始的 logits——它们可以是任意实数,正的、负的、大的、小的,没有直接的含义。要让它们变成"概率",还需要经过 softmax。这就是损失函数要做的事情了。
损失函数:交叉熵
损失函数是训练循环的核心。它决定了模型学什么、怎么学。预训练使用的损失函数是交叉熵损失(Cross-Entropy Loss)。
直觉理解
交叉熵衡量的是:模型给正确答案的概率有多高。
想象模型在每个位置做一道选择题——词表里有 6400 个选项,正确答案只有一个。模型给每个选项打分,分数越高的选项代表模型越"觉得"它是正确答案。交叉熵就是看:模型给正确选项打了多少分?分数越高,损失越小;分数越低,损失越大。
分步过程
具体来说,从 logits 到最终损失,要经过三步:
第一步:softmax —— 把分数变成概率
logits 是原始分数,大小没有约束。softmax 做的事情是把一组分数归一化成概率分布——所有值变成 0 到 1 之间,加起来等于 1。
某个位置的 logits: [1.0, 0.5, -0.3, 2.5, 0.8]
↓ softmax
概率分布: [0.10, 0.06, 0.02, 0.63, 0.08]
总和 = 1.00第二步:找到正确 token 的概率
假设这个位置的正确答案是 token 3,那我们只关心概率分布中第 3 个位置的值——0.63。
第三步:取负对数
交叉熵 = -log(正确 token 的概率) = -log(0.63) = 0.46。
为什么取负对数?因为 log 函数有个好性质:当概率接近 1(预测很准)时,-log 接近 0;当概率接近 0(预测很差)时,-log 趋近无穷大。这正好符合我们对损失的期望:预测越准,损失越小;预测越差,损失越大。
一个对比例子
用一个简化的例子来感受一下。假设词表只有 5 个 token(id: 0-4),某个位置的正确答案是 token 3。
一般预测:
logits: [1.0, 0.5, -0.3, 2.5, 0.8]
softmax 后: [0.10, 0.06, 0.02, 0.63, 0.08]
正确答案: token 3(概率 0.63)
损失 = -log(0.63) = 0.46模型给正确答案的概率是 0.63,不高不低,损失 0.46。
好的预测:
logits: [0.1, 0.0, -0.5, 5.0, 0.2]
softmax 后: [0.01, 0.01, 0.00, 0.95, 0.01]
正确答案: token 3(概率 0.95)
损失 = -log(0.95) = 0.05模型非常确信正确答案是 token 3,概率 0.95,损失只有 0.05。
对比一下就很直观了:预测越准,损失越小。训练的目标就是让所有位置的损失都变小——也就是让模型在每个位置都把高概率给到正确的 token。
最终的损失
模型在每个位置都算出一个交叉熵,最终的损失是所有有效位置的平均值——一个标量(一个数字)。这个数字代表模型在整个 batch 上的整体预测水平。
这里有两个实现细节不需要深究,知道就行:
- logits 的第 i 个位置预测的是第 i+1 个 token,所以代码里 logits 和 labels 做了一个偏移对齐(
logits[..., :-1, :]和labels[..., 1:]) - labels 中值为 -100 的位置不参与计算(上一篇讲过,padding 位置被设为 -100)
反向传播
有了损失(一个标量),接下来就是反向传播。
读者在 00 章节中已经学过反向传播的原理:从损失函数出发,沿着计算图反向传回每一层,用链式法则算出每个参数的梯度。在 LLM 中,计算图是:Embedding → Decoder Block × 8 → LM Head → 交叉熵损失,反向传播就沿着这条路反过来走,从损失一路传回到 Embedding 层的参数。
梯度告诉每个参数两件事:方向(往哪调)和幅度(调多少),最终目标是让损失变小。
MiniMind 的反向传播就一行代码:
scaler.scale(loss).backward()这里的 scaler 是混合精度训练的一部分(下一篇会讲),backward() 就是 PyTorch 自动帮我们做反向传播。计算图在前面构建好了(前向传播 + 损失计算),PyTorch 能自动反向追踪,算出所有参数的梯度。
优化器:AdamW
梯度算出来了,接下来就是用梯度来更新参数。最基础的思路是梯度下降:沿着梯度的反方向走一步,步长由学习率控制。读者已经了解这个原理。
但实际训练 LLM 时,几乎不会用最朴素的梯度下降。MiniMind 用的是 AdamW 优化器,它在梯度下降的基础上做了两个重要改进。
自适应学习率
朴素梯度下降对所参数用相同的学习率。问题在于,有些参数的梯度一直很大(变化剧烈),有些一直很小(变化平缓),统一学习率不合适——梯度大的参数容易冲过头,梯度小的参数学得太慢。
AdamW 的做法是为每个参数维护一份"历史梯度"的统计信息,根据历史梯度自动调整步长:
- 梯度一直很大的参数 → 走小步,避免冲过头
- 梯度一直很小的参数 → 走大步,加快学习
类比一下:下山的时候,陡坡小心翼翼地走,平地大步流星地走。AdamW 自动判断每个参数面临的"地形",给出合适的步长。
权重衰减
AdamW 的另一个改进是权重衰减(Weight Decay)。
正常的梯度下降更新公式是:
其中:
- 是当前参数值
- 是学习率,控制步长大小
- 是梯度,指向损失增加最快的方向(所以减去它就是往损失减小的方向走)
AdamW 在此基础上加了一项:
其中 是衰减系数(通常 0.01~0.1),控制衰减力度。
最后那项 就是权重衰减——它和参数值成正比,参数越大,被拉向 0 的力越强。效果是参数每次更新时都会被"缩小"一点点。
为什么要这样做?因为参数值越大,模型的输入-输出映射就越"剧烈"——输入稍微变一点,输出就天差地别。这种高灵敏度让模型能精确记住每个训练样本的细节(过拟合),但换一组新数据就不行了。权重衰减把参数往 0 的方向拉,限制模型的"自由度",迫使它学到更平滑、更通用的规律。
注意权重衰减是直接作用于参数本身,而不是作用于梯度。旧版的做法(L2 正则化)是把衰减项加到损失函数里,通过梯度间接生效,会和自适应学习率互相干扰。AdamW 直接衰减参数,不受自适应学习率影响,效果更稳定。
一个完整 step 的数据流
把上面讲的四步串起来,看看数据在一步训练中是怎么流动的:
input_ids [32, 340] ← 一个 batch 的训练样本
↓ Embedding
[32, 340, 768] ← 每个 token id 变成 768 维向量
↓ 8 层 Decoder Block
[32, 340, 768] ← 经过 8 层上下文融合
↓ LM Head
logits [32, 340, 6400] ← 每个位置对 6400 个 token 打分
↓ 偏移一位 + softmax + 负对数
交叉熵损失 → 标量(一个数字) ← 整个 batch 的平均损失
↓ 反向传播
梯度 ← 每个参数的调整方向和幅度
↓ AdamW 优化器
参数更新 ← 参数往损失变小的方向走一步每个 step 结束后,模型的参数都变了一点点。然后取下一个 batch,重复同样的流程。训练成千上万个 step 之后,模型的预测就会越来越准——它学会了语言的规律。
代码参考
来看 MiniMind 的训练循环代码(文件:external/minimind/trainer/train_pretrain.py,第 23-72 行)。核心部分是这样的:
def train_epoch(epoch, loader, iters, start_step=0, wandb=None):
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
# 把数据搬到 GPU 上
input_ids = input_ids.to(args.device)
labels = labels.to(args.device)
# ===== 第一步:前向传播 + 计算损失 =====
with autocast_ctx:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss # 交叉熵损失 + MoE 辅助损失
loss = loss / args.accumulation_steps # 梯度累积的均值处理
# ===== 第二步:反向传播 =====
scaler.scale(loss).backward()
if step % args.accumulation_steps == 0:
# ===== 第三步:梯度裁剪 =====
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
# ===== 第四步:参数更新 =====
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)逐行对应一下:
- 前向传播 + 损失计算(第 34-37 行):把
input_ids和labels喂给模型。模型内部做前向传播,算出 logits,然后和 labels 对比计算交叉熵损失。aux_loss是 MoE(混合专家)模型的辅助损失,普通模型没有这个项。 - 反向传播(第 39 行):
.backward()触发反向传播,计算出所有参数的梯度。 - 梯度裁剪(第 42-43 行):把梯度的范数限制在
args.grad_clip以内。如果某个 step 的梯度特别大(比如遇到了一个特别难的样本),直接更新可能导致参数剧烈抖动。梯度裁剪就是给梯度加一个上限,防止这种情况。 - 参数更新(第 45-48 行):优化器根据梯度更新参数,然后清空梯度(为下一个 step 做准备)。
这里的 scaler 和 autocast_ctx 是混合精度训练相关的,accumulation_steps 是梯度累积相关的。这些都是让训练跑得更稳、更快的工程技巧,下一篇我们会专门讲。
小结
训练循环的核心就四步:
前向传播(logits)→ 交叉熵损失 → 反向传播(梯度)→ AdamW 参数更新其中交叉熵损失是灵魂——它把"模型预测好不好"量化成了一个数字,驱动整个学习过程。
几个要点回顾:
- 前向传播:和推理流程一样,区别在于训练时所有位置的 logits 都有意义
- 交叉熵:-log(正确 token 的概率)。预测越准,损失越小
- 反向传播:从损失反向传回所有参数,算出梯度
- AdamW:自适应学习率 + 权重衰减,比朴素梯度下降更适合训练 LLM
下一篇我们看让训练实际跑起来的工程细节——学习率调度、梯度累积、混合精度训练等。这些不影响原理,但决定了训练能不能稳定、高效地跑完。