训练细节:让训练跑稳、跑快
上一篇讲了训练循环的四步:前向传播 → 交叉熵损失 → 反向传播 → 参数更新。这是训练的核心逻辑。但实际把训练跑起来,还需要处理一些工程细节——学习率不是一成不变的,显存可能不够用,梯度偶尔会"发疯",训练中途可能断电。这些细节不影响你对训练原理的理解,但决定了训练能不能跑稳、跑快。
这一篇我们就来看看这些"让训练实际跑起来"的关键技巧。
学习率调度:warmup + cosine decay
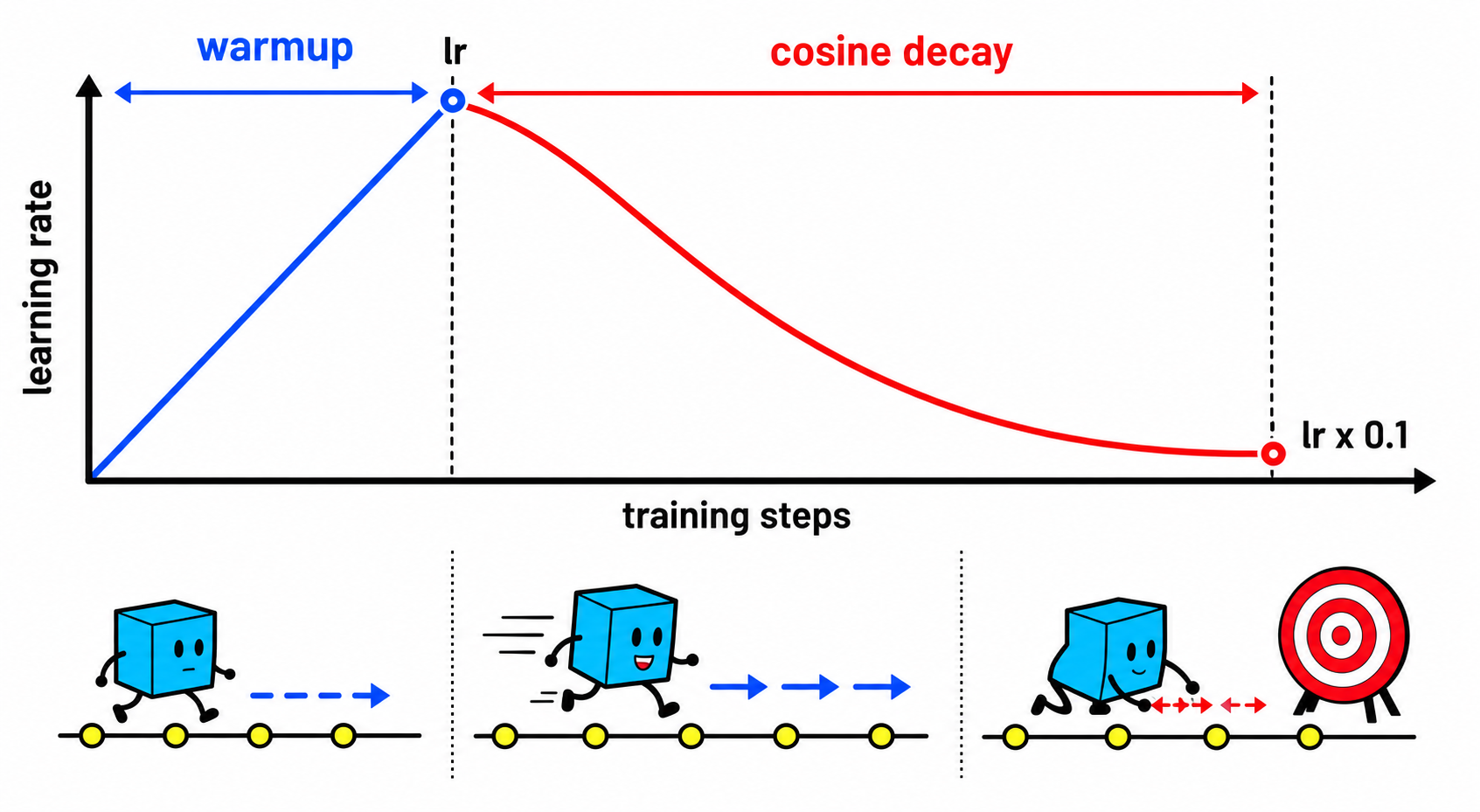
问题在哪
MiniMind 的学习率设置了 5e-4(0.0005)。读者可能会想:这个学习率是一开始就用、一直不变的吗?
答案是:不是。学习率在训练过程中是动态变化的,而且变化的方式对训练效果影响很大。
问题在于:训练刚开始的时候,模型参数是随机的,梯度方向也很不稳定——同一个参数,这个 step 的梯度说往左,下个 step 可能就改成往右了。如果这时候直接用大学习率,参数就会朝不确定的方向猛冲,可能冲到很远、很难恢复的地方。打个比方,你站在一片陌生的荒野中,完全不知道目的地在哪,这时候不应该全力冲刺——应该先慢走,确定大致方向再说。
warmup:先慢后快
warmup(预热)就是解决这个问题的。训练的前几个 step,用一个很小的学习率,让模型先在参数空间里摸索一下,找到大致的"好方向"。等梯度方向稳定了,再逐步加大学习率,开始快速学习。
举个具体的例子:假设目标学习率是 5e-4,warmup 阶段可能从 5e-5(目标的 10%)开始,在几百步内线性增长到 5e-4。这个过程中,模型慢慢从"什么都不知道"过渡到"有了一个大致方向",然后才用正常的学习率开始快速学习。
cosine decay:后期减速
训练后期,模型已经学到了大量知识,参数处在一个不错的位置。这时候如果学习率还很大,参数就会在好位置附近来回震荡,很难进一步精调。就好比调收音机频道——大致找到电台后,要微调旋钮慢慢找到最清晰的位置,而不是继续大幅度拧。
cosine decay(余弦衰减)就是在训练后期按余弦曲线逐渐减小学习率,让模型在好的参数附近做精细调整。之所以选择余弦曲线而不是线性衰减,是因为余弦曲线的变化更平滑——前期降得慢(模型还在快速学习),后期降得快(快速收敛到精细位置),中间过渡自然。
MiniMind 的实现
MiniMind 的学习率调度公式是:
lr × (0.1 + 0.45 × (1 + cos(π × 当前步数 / 总步数)))我们看看两个极端值:
- 训练开始时(当前步数 = 0):cos(0) = 1,所以系数 = 0.1 + 0.45 × 2 = 1.0,学习率 = lr × 1.0
- 训练结束时(当前步数 = 总步数):cos(π) = -1,所以系数 = 0.1 + 0.45 × 0 = 0.1,学习率 = lr × 0.1
整体趋势是:学习率从 lr 开始,按照余弦曲线平滑地降到 lr × 0.1。前期学习率高,模型快速学习;后期学习率逐渐降低,模型慢慢精调。
用一个类比来理解:学开车。刚上车时先慢速摸方向盘,熟悉车的感觉(warmup);然后在直道上加速行驶(学习率保持较高);快到目的地时逐渐减速,精准停到车位里(cosine decay)。整个过程不是匀速的,而是有快有慢,跟训练的学习率调度一个道理。
需要注意的是,MiniMind 的公式中没有显式的 warmup 阶段——它直接从满学习率开始。对于小模型和小数据集,这种简单的余弦衰减已经够用了。大规模训练通常会在前面额外加一段 warmup 阶段(比如前 2000 步线性增长到目标学习率),但核心思路是一样的:前期不冒进,后期慢慢收。
批次大小与梯度累积
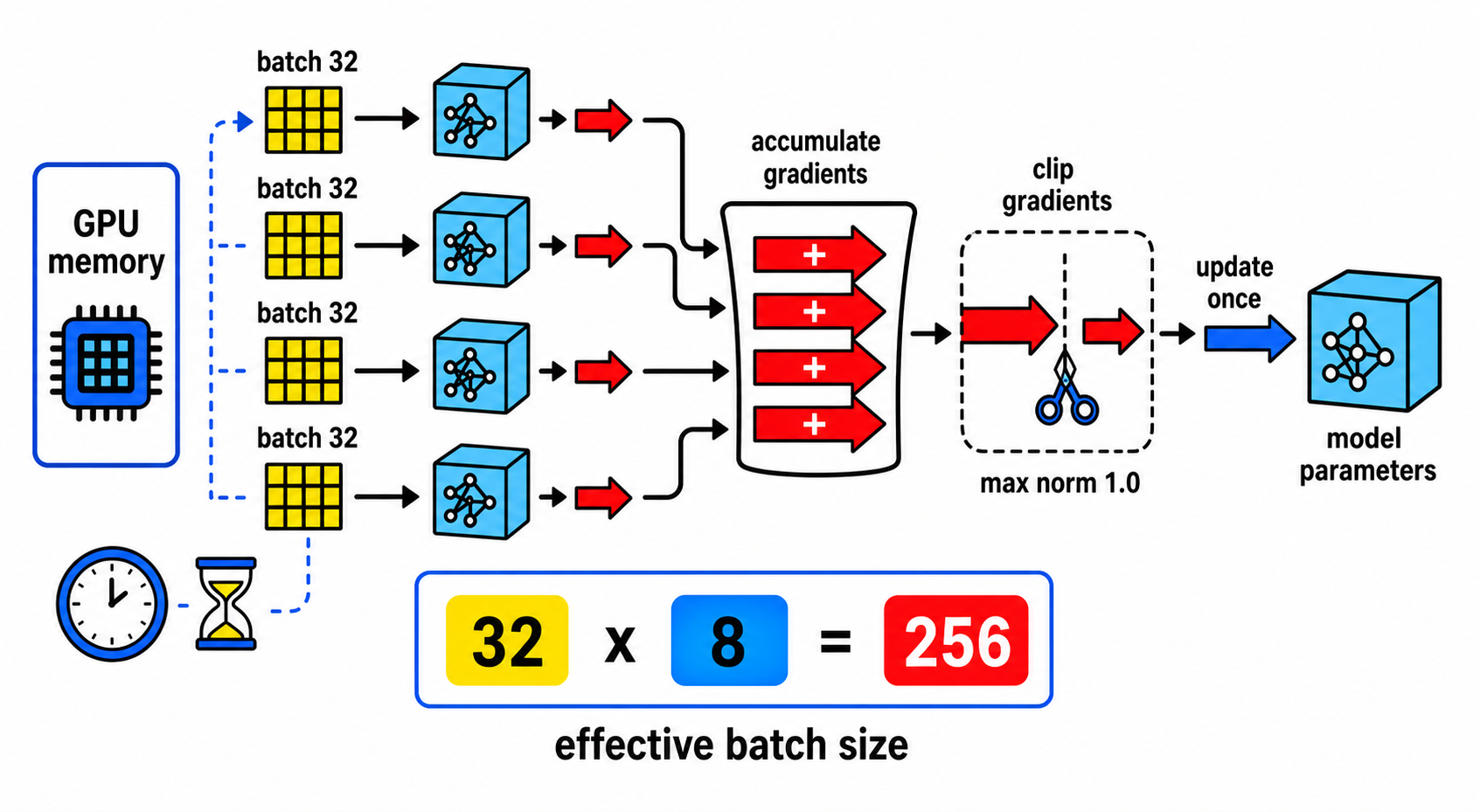
batch size 的权衡
训练时每次取多少个样本一起算,就是 batch size。上一篇文章里一直在用的 32 就是 batch size——每次取 32 个训练样本,一起做前向传播和反向传播。
batch size 的大小需要权衡:
- 大 batch(比如 256):一次看很多样本,梯度估计更准确(噪声小),训练更稳定。但需要更多 GPU 显存——每个样本都要算前向和反向,32 个样本的中间结果和 256 个样本的中间结果,显存占用差了 8 倍。
- 小 batch(比如 32):显存友好,但梯度估计不稳定。打个比方,你想了解一个班级的平均成绩,问 32 个人和问 256 个人,后者得到的结果更可靠。
顺便解释两个后面会反复出现的概念:每处理一个 batch(走一遍前向→损失→反向→更新的完整循环)就是一个 step(步)。把所有训练数据完整过一遍就是一个 epoch(轮)。假设有 10000 个样本,batch_size=32,那一个 epoch 就是约 312 个 step。MiniMind 训练 2 个 epoch,就是把所有数据从头到尾看两遍。
梯度累积:用时间换空间
如果显存不够用大 batch,但又想要大 batch 的训练稳定性,怎么办?梯度累积(Gradient Accumulation)就是一种"用时间换空间"的技巧——用多个小 batch 模拟一个大 batch 的效果。
具体做法:
- 正常取一个小 batch(比如 32 个样本),做前向传播和反向传播,算出梯度。但这时候不更新参数,而是把梯度留在内存里。
- 再取下一个小 batch,做同样的事,梯度会累加到上一步的梯度上。
- 重复 8 次之后,梯度是 8 个小 batch 累加的结果。这时候才做一次参数更新,然后清零梯度。
从参数更新的角度看,效果等价于一次用了 32 × 8 = 256 个样本——等效 batch size = 256。代价是训练变慢了 8 倍(要跑 8 次前向和反向才更新一次),但对于显存不够的情况,这是一个很实用的权衡。
但有一个细节:因为梯度是累加的,损失也要相应地除以累积步数,这样累积后的平均梯度才正确:
loss = loss / args.accumulation_steps # 损失除以 8如果不除以 8,累加 8 次之后梯度就变成了 8 倍大,参数更新就会太猛,相当于等效学习率放大了 8 倍——和学习率调度的初衷完全相反。
用一个类比:考试时把 8 张小卷子拼成一张大卷子。每张小卷子单独做、单独算分,最后把 8 张卷子的总分取平均,和一次性做一张大卷子的效果是一样的。只不过你不用同时把 8 张卷子摊在桌上(不需要那么大的显存),而是一张一张做(用更多时间)。
梯度裁剪
为什么需要裁剪
训练过程中,大部分时候梯度的幅度是正常的。但偶尔会遇到一些特殊的 batch,让梯度变得异常大——比如一个包含很罕见词汇的样本,或者模型预测非常差的样本。如果直接用这个异常大的梯度更新参数,参数可能一下子跳到很远的地方,之前的努力就白费了。严重的话,训练会直接崩溃(loss 突然变成 NaN)。
怎么裁剪
模型有上百万个参数,每个参数都有一个梯度。梯度裁剪要回答的问题是:这上百万个梯度加在一起,总步长有多大?
要算"总步长",先把所有参数的梯度拼成一个大向量,然后算它的"长度"。这里用的"长度"叫做 L2 范数——就是把向量中每个元素的平方加起来,再开根号:
总长度 = √(梯度₁² + 梯度₂² + ... + 梯度ₙ²)如果总长度超过了预设的阈值,就把所有梯度等比缩小,让总长度刚好等于阈值。方向不变,只是步长被限制了:
if 总长度 > 阈值:
所有梯度 *= (阈值 / 总长度) # 等比缩小MiniMind 的阈值设为 1.0:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)类比一下:不管地图告诉你目的地有多远,每一步最多走 1 公里。方向照着地图走,但步长有上限。这样即使地图偶尔给了一个离谱的距离,你也不会一步跨到沟里去。
有一点要说明:梯度裁剪和梯度累积是两个独立的机制,互不影响。梯度累积是"攒几步再更新",梯度裁剪是"限制每步的步长"。在 MiniMind 的代码中,裁剪发生在累积完成后、参数更新前——先攒够梯度,然后检查总长度有没有超标,超标就裁剪,最后才更新参数。
训练监控
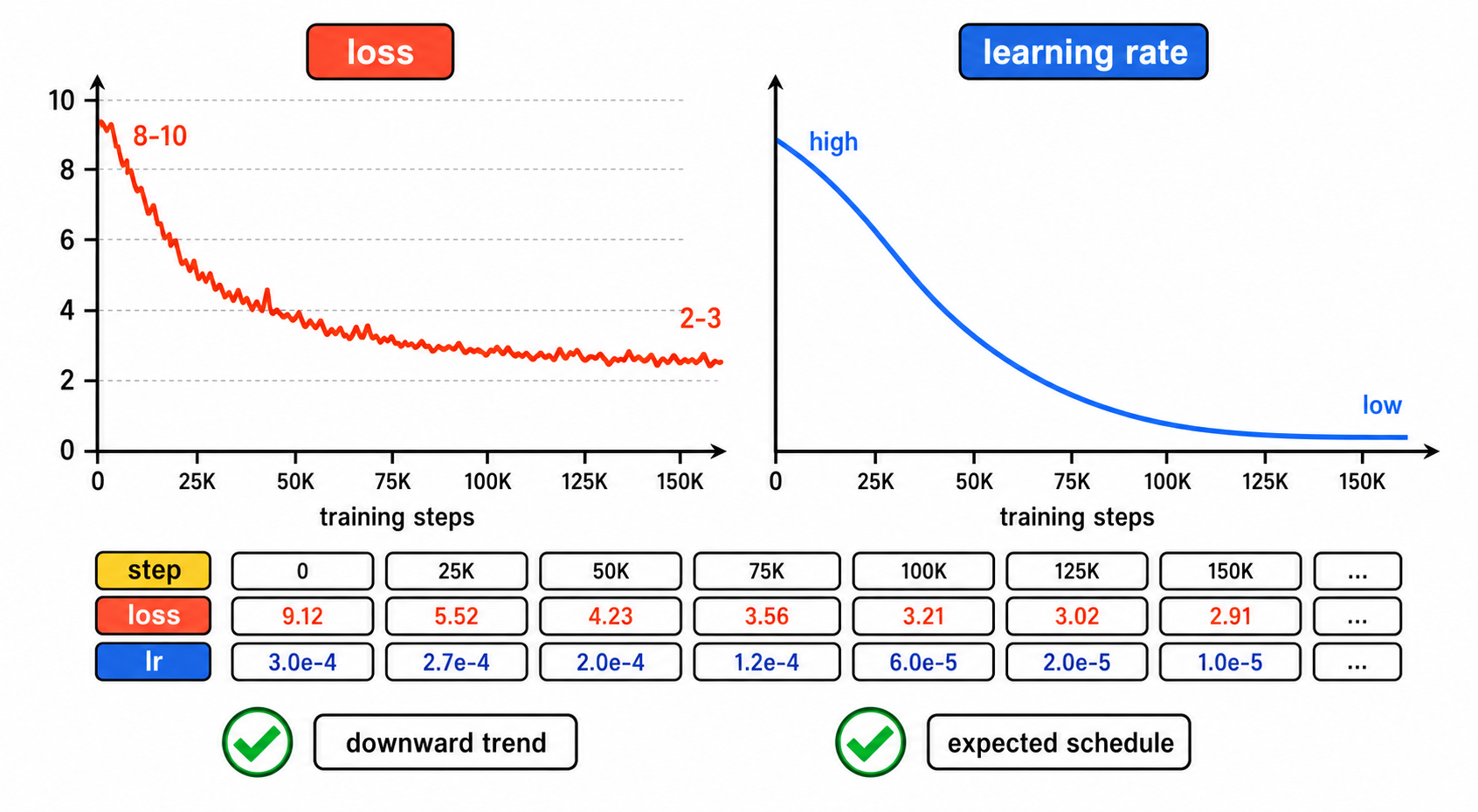
训练跑起来之后,怎么知道它在正常学习?光等它跑完再检查结果是不行的——如果训练方向从一开始就错了,跑了几个小时等于白费。所以训练过程中需要持续监控。最直接的方式就是看训练日志。MiniMind 每 100 步打印一次,主要关注这几个指标:
loss 曲线
正常情况下,loss 应该持续下降。从训练初期的 8-10(接近随机预测的损失——词表有 6400 个 token,随机猜的损失约 ln(6400) ≈ 8.76),逐步降到 2-3 甚至更低。这说明模型在一点一点学会预测下一个 token。下降的速度通常是"先快后慢"——前期模型什么都不会,随便学一点就有明显进步;后期提升越来越难,loss 下降越来越慢。
如果 loss 不降反升,通常有两个原因:学习率太大,或者数据有问题。这时候就需要调小学习率或者检查训练数据的质量。
perplexity
perplexity(困惑度)是 loss 的另一种表达方式,公式是:
直觉上,perplexity 回答了这样一个问题:在每个位置上,模型平均在多少个选项之间犹豫?比如 perplexity = 10,意味着模型觉得"下一个 token 大概是这 10 个中的一个"。perplexity 越低,说明模型越确定,预测越准。
举个例子:训练初期 loss 大约是 8-9,对应的 perplexity 大约是 3000-8000——模型几乎在半个词表里瞎猜。训练后期 loss 降到 3 左右,perplexity 大约是 20——模型只需要在 20 个候选中做选择,精准多了。
看什么、怎么判断
实际训练时,关注两点就够了:
- loss 是否在持续下降。不需要每步都降,但整体趋势应该是向下的。偶尔小幅上升是正常的(某个 batch 特别难),但如果连续几百步都在涨,就要排查问题了。
- 学习率的变化是否符合预期。日志会打印当前学习率,确认它确实在按余弦曲线变化,而不是卡住不动。
MiniMind 的日志格式长这样:
Epoch:[1/2](100/5000), loss: 7.8234, logits_loss: 7.8000, aux_loss: 0.0234, lr: 0.00049876, epoch_time: 12.3min一眼就能看到:当前 epoch/总 epoch、当前 step/总 step、各项损失、当前学习率、预计剩余时间。这些信息足够判断训练是否正常。
混合精度训练
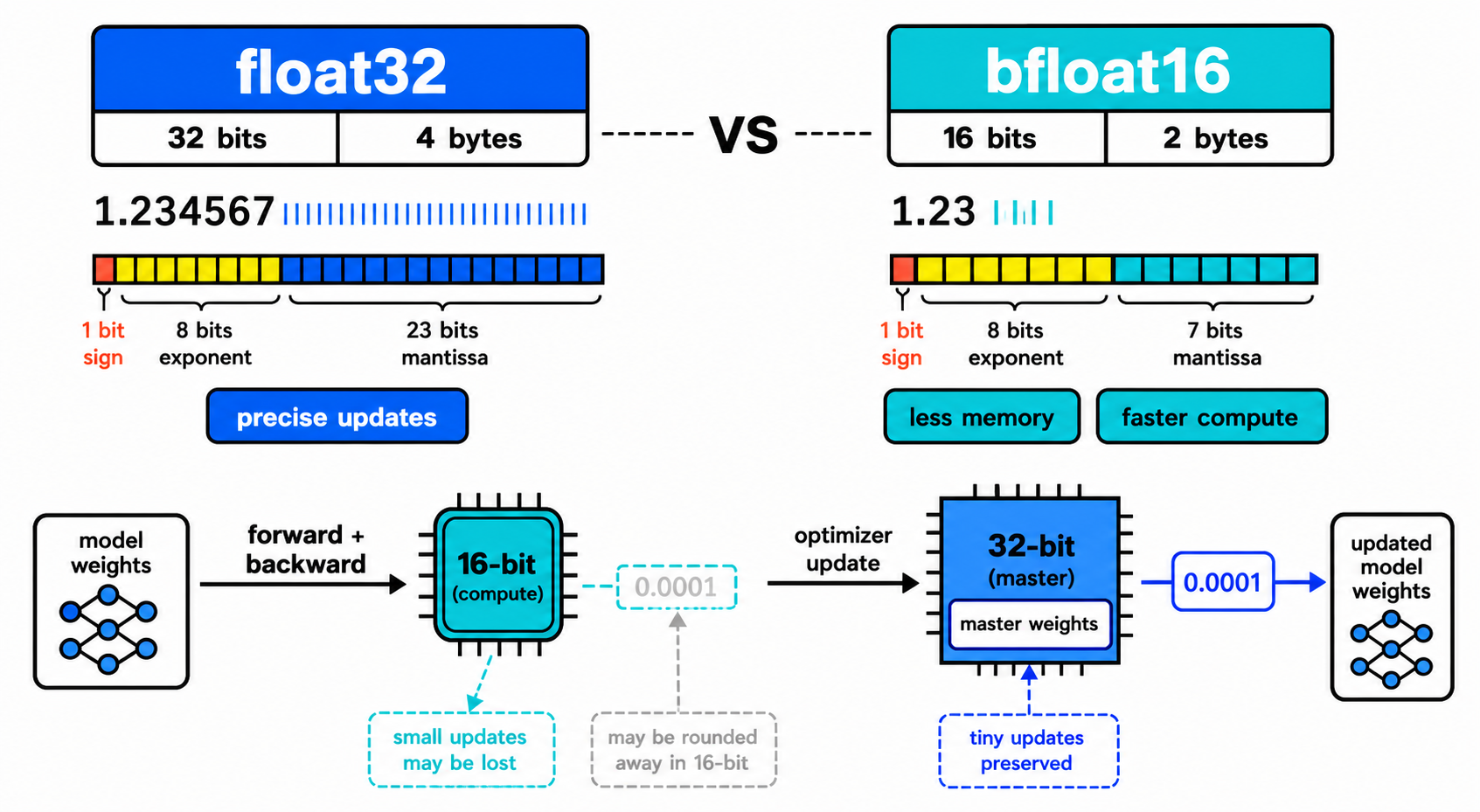
为什么要用低精度
默认情况下,PyTorch 用 float32(32 位浮点数)来存储和计算所有数值。每个参数、每个中间结果都占 4 个字节。对于一个小模型可能无所谓,但 LLM 有几百万甚至几十亿个参数,加上训练时的中间结果,显存很快就满了。
而且 float32 的计算速度也更慢——GPU 处理 16 位数据的速度是 32 位的两倍。
做法:前向和反向用 16 位,参数更新用 32 位
混合精度训练(Mixed Precision Training)的核心思路是:不是所有计算都需要 32 位那么高的精度。具体来说:
- 前向传播和反向传播:用 bfloat16(16 位浮点数)计算。bfloat16 的数值范围和 float32 一样大,只是精度低一点(小数点后少几位)。大部分计算不需要那么高的精度,16 位完全够用。模型的参数本身也存一份 bfloat16 的副本,用于前向计算。
- 参数更新:用 float32。模型维护一份 float32 的"主副本"参数,优化器(AdamW)基于 float32 的参数和梯度来做更新,保证参数更新的准确性。每次更新后,把 float32 参数重新转成 bfloat16,用于下一次前向计算。
为什么安全
精度丢失确实发生了,但关键在于:丢失的精度不影响方向,只影响方向的精确程度。
前向和反向传播算的是梯度和中间结果。梯度告诉模型的是"往哪个方向调参数"——它本身就是一个近似值(基于当前 batch 的有限样本估计的),本来就不是精确的。从 float32 降到 bfloat16,相当于在一个本来就不精确的方向上多了一点噪声,但大方向没变。
参数更新用 float32 就不同了。这里做的是精细调整——学习率通常很小(0.0005),每次更新量也很小。如果参数和更新都用 16 位,小更新量会被直接截断。比如参数值是 1.234,更新量是 0.0001,bfloat16 可能表示不了这种精细的差异,更新就被"吞掉"了。累积几万步下来,这些被吞掉的更新就变成了明显的误差。
所以分工是:16 位负责算方向(不需要那么精确),32 位负责存参数和做精细调整(差一点都不行)。
另外,bfloat16 和另一种 16 位格式 float16 有个关键区别:bfloat16 的指数位数和 float32 一样多,所以数值范围一样大——不会出现"数字太大导致溢出"的问题。它只是牺牲了一些小数精度,但对于神经网络来说,这点精度损失几乎不影响结果。
效果
混合精度的效果很直接:显存占用大约减半,计算速度接近翻倍,模型质量几乎不受影响。这是一个几乎免费的加速,几乎所有现代 LLM 训练都会用。
需要注意的是,混合精度需要硬件支持。NVIDIA 的 Ampere 及以后架构(如 A100、RTX 30 系列及更新)对 bfloat16 有原生支持,效果最好。较老的 GPU 可能只支持 float16,这时候需要配合 GradScaler(梯度缩放器)来防止数值下溢——MiniMind 代码中的 scaler 就是做这件事的。
MiniMind 默认使用 bfloat16:
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16检查点保存
为什么需要检查点
训练一个 LLM 需要很长时间——即使 MiniMind 这种小模型,在单张 GPU 上也要跑好几个小时。大模型甚至要跑几周。训练过程中可能遇到各种意外:断电、程序报错、硬件故障……如果没有保存中间结果,就得从头开始训练,损失巨大。
检查点(Checkpoint)就是训练过程中的"存档",和玩游戏时的存档一个道理——定期把当前状态保存下来,出了问题就读档重来。对于训练来说,就是定期把训练状态保存到硬盘上,出问题了就从最近的检查点恢复,不用从头来。
保存什么
一个完整的检查点包含三部分:
- 模型参数:当前所有参数的值。这是最重要的部分,有了它就能恢复模型。
- 优化器状态:AdamW 优化器内部维护了每个参数的历史梯度信息(一阶矩和二阶矩的滑动平均)。这些信息是优化器"记住"的历史,丢了的话优化器就"失忆"了,需要重新积累。
- 训练进度:当前训练到第几个 epoch、第几个 step。恢复训练时可以从断点继续,而不是从头开始。
保存优化器状态经常被忽略,但其实很重要。如果没有优化器状态,恢复训练时 AdamW 的历史信息就全丢了,相当于优化器重新开始——这会导致恢复后的训练不稳定,可能需要几百步才能重新找回节奏。
MiniMind 每 1000 步保存一次检查点。这意味着最坏情况下,只会损失 1000 步的训练进度。保存频率可以根据实际情况调整——保存太频繁会拖慢训练(写硬盘需要时间),保存太稀疏则断电后损失更大。
还有一个细节:保存检查点时会先把模型切换到 eval 模式,保存完再切回 train 模式。这是因为训练中的模型可能有一些只在训练时才有效的状态(比如 Dropout),保存时需要用干净的状态。
代码参考
最后,把上面讲的各个细节对应到 MiniMind 的代码中。
学习率调度
学习率的计算公式在 trainer_utils.py 第 40-41 行:
# 余弦衰减:从 lr × 1.0 降到 lr × 0.1
def get_lr(current_step, total_steps, lr):
return lr * (0.1 + 0.45 * (1 + math.cos(math.pi * current_step / total_steps)))训练循环中每个 step 动态设置学习率(train_pretrain.py 第 30-32 行):
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr梯度累积和裁剪
train_pretrain.py 第 37-48 行,梯度累积和裁剪配合使用:
loss = loss / args.accumulation_steps # 损失除以累积步数(梯度累积)
scaler.scale(loss).backward() # 反向传播,梯度累加到内存
if step % args.accumulation_steps == 0: # 每 8 步才做一次更新
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip) # 梯度裁剪
scaler.step(optimizer) # 参数更新
scaler.update()
optimizer.zero_grad(set_to_none=True) # 清零梯度注意流程顺序:反向传播(梯度累加)→ 梯度裁剪 → 参数更新 → 梯度清零。这个顺序很重要——先累加完梯度,再裁剪防溢出,然后才安全地更新参数。
混合精度
train_pretrain.py 第 119-121 行,混合精度的设置:
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)训练循环中用 autocast_ctx 包裹前向传播,自动把计算转到 16 位精度。在 CPU 上训练时 autocast_ctx 是空操作(nullcontext),因为混合精度主要针对 GPU。
检查点保存
train_pretrain.py 第 60-70 行,每 1000 步保存一次:
if (step % args.save_interval == 0 or step == iters) and is_main_process():
model.eval()
# 保存模型权重(纯参数,用于推理)
raw_model = model.module if isinstance(model, DistributedDataParallel) else model
state_dict = raw_model.state_dict()
torch.save({k: v.half().cpu() for k, v in state_dict.items()}, ckp)
# 保存完整检查点(含优化器状态,用于恢复训练)
lm_checkpoint(lm_config, weight=args.save_weight, model=model, optimizer=optimizer, ...)
model.train()这里保存了两份文件:一份只包含模型参数(用于推理,体积小),一份包含完整训练状态(用于恢复训练,体积大)。训练结束后只需要第一份,第二份是训练过程中的保险。
小结
这一篇讲的都是在训练循环"外面"的工程细节,它们不改变训练的原理,但决定了训练能不能稳定、高效地跑完:
学习率调度:先快后慢,按余弦曲线从 lr 降到 lr × 0.1
梯度累积:多个小 batch 模拟一个大 batch,用时间换空间
梯度裁剪:限制梯度的总长度,防止某一步走太远
混合精度:前向和反向用 16 位,参数更新用 32 位,显存减半速度翻倍
检查点保存:定期存档,防止意外中断后从头训练用一个类比来总结:训练 LLM 就像跑一场马拉松。学习率调度是配速策略——开始稳住节奏,中段发力,最后冲刺精调;梯度累积是分段跑——不能一口气跑完就分几段,效果差不多;梯度裁剪是限速——不管下坡有多陡,步子不能迈太大;混合精度是轻装上阵——不是所有装备都要带最重的;检查点是补给站——定期补给,出了状况能回退。
下一篇是预训练这一章的最后一篇,我们做一个全章回顾,把数据准备、训练循环、工程细节串成一条线。