推理过程回顾
这一章我们从 MiniMind 的视角,走完了大语言模型推理的完整流程。下面把每一步串起来,形成一条完整的链路。
从用户提问到模型回答
假设用户输入了一个问题:
为什么天空是蓝色的?最终模型输出了回答。这中间发生了什么?可以把整个过程压缩成这条主线:
用户提问
-> 套聊天模板
-> tokenizer 切成 token id
-> token id 查表变成向量
-> 加入位置信息
-> 多层 Decoder Block 结合上下文
-> LM Head 输出 logits
-> 采样选出一个 token
-> 拼回上下文,继续预测
-> 直到生成结束符或达到最大长度下面按顺序回顾每一步做了什么。
每一步的职责
套聊天模板:把用户的原始问题整理成模型熟悉的对话格式,加上角色标记、system 指令、历史消息等。模型看到的是整段模板化后的文本,而不是用户单独的问题。
切成 token:tokenizer(通常用 BPE 算法)把模板化后的文本按规则切成一段段 token,再查词表转成 token id。token 不一定是字或词,而是 tokenizer 词表里的文本片段。
为什么天空是蓝色的?
-> 为什么 / 天空 / 是 / 蓝色 / 的 / ?
-> [128, 923, 17, 2048, 9, 64]Token Embedding + 位置编码:token id 本身只是编号,模型不能直接用来计算。Token Embedding 把每个 id 查表转换成向量,位置编码再给每个位置加上顺序信息。两个向量相加后,进入模型主体。
token id 序列 -> 查表得到向量矩阵 -> 加上位置信息 -> 10×128 矩阵多层 Decoder Block:这是模型的核心。每一层 Decoder Block 都会做三件事:
Self-Attention:让每个位置参考前文,把上下文信息读进来
Add & Norm:保留原始信息,同时稳定数值
Feed Forward:对每个位置的向量做进一步加工经过一层 Decoder Block,矩阵形状不变(仍然是 10×128),但每个位置的向量已经带上了前文信息。多层 Decoder Block 堆叠后,信息会逐步累积,最后一个位置的向量就代表了模型读完整段上下文后的"当前状态"。
LM Head 输出 logits:模型取最后一个位置的向量,交给 LM Head。LM Head 会给词表里的每个 token 打一个分数,这些分数就是 logits。
最后一个位置的 128 维向量 -> LM Head -> 6400 个 logit 分数采样一个 token:logits 还不是最终答案。推理程序会先经过一系列处理,再从候选里选出一个 token:
用 temperature 调整随机程度
-> 对已出现的 token 做重复惩罚
-> 用 top-k 过滤低排名候选
-> 用 top-p 保留累计概率合理的候选集合
-> softmax 得到概率分布
-> 用 multinomial 采样抽出一个 token如果关闭随机采样,最后一步会直接选概率最高的 token(argmax)。
拼回上下文,循环生成:选出的 token 被接回原来的输入后面,成为下一轮预测的一部分。模型基于新的上下文再次预测,直到生成结束符或达到最大长度。
预测 -> 采样 -> 拼接 -> 再预测 -> 再采样 -> ... -> 结束大模型不是一次性写完整篇答案,而是一步一步"接龙"出来的。
一张图串起来
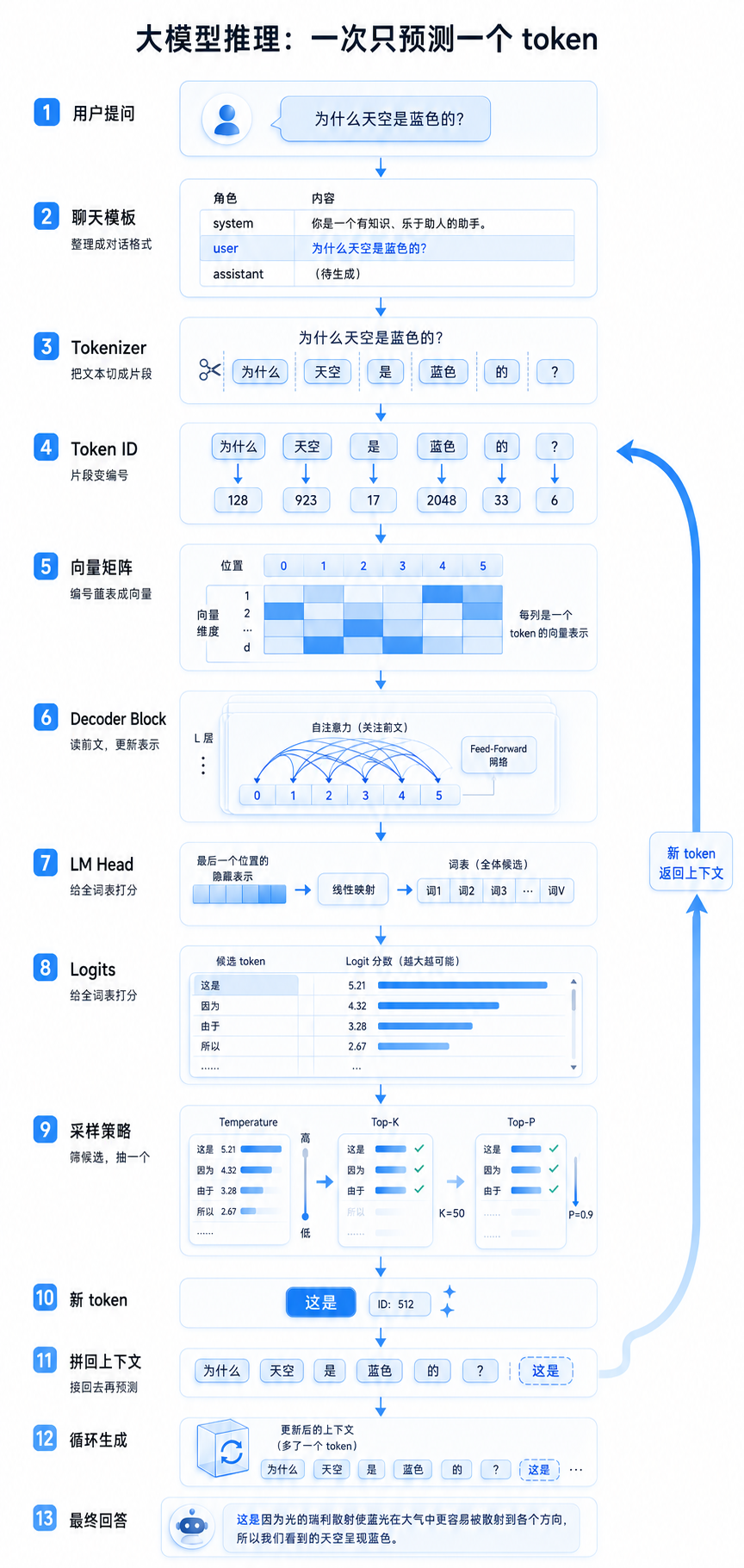
用户提问:"为什么天空是蓝色的?"
-> 套聊天模板:用户:为什么天空是蓝色的?\n助手:
-> tokenizer 切分:[为什么, 天空, 是, 蓝色, 的, ?, 助手, :]
-> token id:[128, 923, 17, 2048, 9, 64, 301, 88]
-> Token Embedding + 位置编码 -> 8×128 向量矩阵
-> 多层 Decoder Block(自注意力 -> 残差归一化 -> 前馈网络 -> 残差归一化)
-> 取最后位置的向量 -> LM Head -> logits(词表大小个分数)
-> 采样(temperature -> 重复惩罚 -> top-k -> top-p -> multinomial)
-> 选出 token:"这是" (id=512)
-> 拼回上下文:用户:为什么天空是蓝色的?\n助手:这是
-> 继续预测下一个 token ...
-> 生成结束符或达到最大长度 -> 输出最终回答推理不是一次完成
整个过程中有几个值得注意的点:
第一,推理是循环。模型每生成一个 token,都要把新 token 拼回输入,重新跑一遍 Embedding + Decoder Block + LM Head + 采样。生成长回答时,这个循环可能跑几百甚至上千次。
第二,每一步都在预测概率。模型不是直接输出"下一个词是什么",而是给所有候选 token 打分。采样策略决定了最终选哪个——可以选最确定的,也可以按概率随机抽。
第三,Decoder Block 是核心计算模块。模型的大部分参数都在这里。它做的事情可以概括成:让每个位置参考前文,把孤立 token 的向量逐步加工成带上下文的向量。
关键概念速查
token:模型处理文本的基本单位,由 tokenizer 从文本中切出
token id:token 在词表中的编号
prompt:套完模板后的完整输入文本
Token Embedding:把 token id 查表变成向量
位置编码:告诉模型每个 token 在哪个位置
Decoder Block:结合上下文更新向量,包含 Self-Attention、Add & Norm、Feed Forward
hidden state:Decoder Block 输出的向量矩阵
LM Head:把最后位置的 hidden state 映射成 logits
logits:每个候选 token 的原始分数
采样:从 logits 中选出一个 token,涉及 temperature、top-k、top-p 等策略
上下文窗口:模型当前能看到的所有 token用代码跑通推理:一个最小的 Transformer
下面用纯 JavaScript 实现一个最小的 Decoder-Only Transformer,不依赖任何外部库。词表只有 30 个字符(a-z + 空格 + 逗号 + 句号 + 结束符),Decoder Block 只有 1 层,向量维度 16。所有权重直接写在代码里。
完整可运行版本(包含推理 + 训练)见项目根目录的 tinymind.js,运行 node tinymind.js 即可看到训练 loss 下降和推理输出变化。
这段代码的目的不是做出一个聪明的模型,而是让你亲手跑通整条推理链路:文本进去,token id 出来,经过 Embedding、位置编码、Decoder Block、LM Head、采样,最终生成新的文本。
词表与分词
先把词表定义出来。每个字符对应一个 id,多一个 <eos> 作为结束符:
// 词表:26 个小写字母 + 空格 + 逗号 + 句号 + <eos>,共 30 个 token
var chars = "abcdefghijklmnopqrstuvwxyz ,.";
var EOS_ID = chars.length; // 29
var VOCAB_SIZE = chars.length + 1; // 30
// 文本 -> token id 列表
function tokenize(text) {
var ids = [];
for (var i = 0; i < text.length; i++) {
var idx = chars.indexOf(text[i]);
ids.push(idx >= 0 ? idx : chars.indexOf(" "));
}
return ids;
}
// token id 列表 -> 文本
function detokenize(ids) {
var text = "";
for (var i = 0; i < ids.length; i++) {
if (ids[i] === EOS_ID) break;
text += chars[ids[i]];
}
return text;
}tokenize 逐字符查表,detokenize 把 id 变回文本。遇到 <eos> 就停。
权重初始化与矩阵运算
模型内部全是矩阵运算。这里用一个固定种子的伪随机数生成器来初始化所有权重,保证每次运行结果一样:
var EMBED_DIM = 16; // 向量维度
var D_FF = 64; // Feed Forward 中间层维度
// 固定种子的伪随机数生成器
function createRng(seed) {
var s = seed;
return function () {
s = (s * 1103515245 + 12345) & 0x7fffffff;
return s / 0x7fffffff;
};
}
// 生成一个 rows × cols 的随机矩阵,用于初始化权重
function randomMatrix(rows, cols, rng, scale) {
var m = [];
for (var i = 0; i < rows; i++) {
var row = [];
for (var j = 0; j < cols; j++) row.push((rng() - 0.5) * scale);
m.push(row);
}
return m;
}
// 矩阵乘法:a(m×k) × b(k×n) = c(m×n)
function matMul(a, b) {
var m = a.length, k = a[0].length, n = b[0].length;
var c = [];
for (var i = 0; i < m; i++) {
var row = [];
for (var j = 0; j < n; j++) {
var sum = 0;
for (var p = 0; p < k; p++) sum += a[i][p] * b[p][j];
row.push(sum);
}
c.push(row);
}
return c;
}
// 向量点积
function dot(a, b) {
var sum = 0;
for (var i = 0; i < a.length; i++) sum += a[i] * b[i];
return sum;
}
// softmax:把一串数字变成概率分布(加起来等于 1)
function softmax(arr) {
var max = arr[0];
for (var i = 1; i < arr.length; i++) {
if (arr[i] > max) max = arr[i];
}
var exps = [], sum = 0;
for (var i = 0; i < arr.length; i++) {
exps.push(Math.exp(arr[i] - max));
sum += exps[i];
}
return exps.map(function (e) { return e / sum; });
}
// Layer Norm:让每个位置的向量数值更稳定
function layerNorm(x) {
var mean = 0;
for (var i = 0; i < x.length; i++) mean += x[i];
mean /= x.length;
var variance = 0;
for (var i = 0; i < x.length; i++) variance += (x[i] - mean) * (x[i] - mean);
variance /= x.length;
var result = [];
for (var i = 0; i < x.length; i++) {
result.push((x[i] - mean) / Math.sqrt(variance + 1e-5));
}
return result;
}
// 残差连接 + LayerNorm:把原始输入和新的输出加起来,再做归一化
function addNorm(a, b) {
var result = [];
for (var j = 0; j < a.length; j++) result.push(a[j] + b[j]);
return layerNorm(result);
}addNorm 把"残差连接 + LayerNorm"合在一起——这个操作在 Decoder Block 里会出现两次。
单层 Decoder Block
这是模型的核心。一层 Decoder Block 包含 Self-Attention、残差连接 + Layer Norm、Feed Forward、再残差连接 + Layer Norm:
// 初始化模型权重
var rng = createRng(42);
// Embedding 表:每个 token id 查表得到一个 EMBED_DIM 维向量
var embedding = randomMatrix(VOCAB_SIZE, EMBED_DIM, rng, 0.8);
// Self-Attention 的 Q/K/V/O 投影矩阵
var Wq = randomMatrix(EMBED_DIM, EMBED_DIM, rng, 0.5);
var Wk = randomMatrix(EMBED_DIM, EMBED_DIM, rng, 0.5);
var Wv = randomMatrix(EMBED_DIM, EMBED_DIM, rng, 0.5);
var Wo = randomMatrix(EMBED_DIM, EMBED_DIM, rng, 0.5);
// Feed Forward 的两层权重(先升维到 D_FF,再降维回 EMBED_DIM)
var W1 = randomMatrix(EMBED_DIM, D_FF, rng, 0.5);
var W2 = randomMatrix(D_FF, EMBED_DIM, rng, 0.2);
// LM Head:把 EMBED_DIM 维向量映射成 VOCAB_SIZE 个分数
var Wlm = randomMatrix(EMBED_DIM, VOCAB_SIZE, rng, 0.5);
// Sinusoidal 位置编码(经典 Transformer 做法)
function positionalEncoding(seqLen) {
var pe = [];
for (var pos = 0; pos < seqLen; pos++) {
var row = [];
for (var i = 0; i < EMBED_DIM; i++) {
var angle = pos / Math.pow(10000, (2 * Math.floor(i / 2)) / EMBED_DIM);
row.push(i % 2 === 0 ? Math.sin(angle) : Math.cos(angle));
}
pe.push(row);
}
return pe;
}
// 因果 Self-Attention:每个位置只能看自己和前面的位置
function selfAttention(x) {
var Q = matMul(x, Wq);
var K = matMul(x, Wk);
var V = matMul(x, Wv);
var scale = 1.0 / Math.sqrt(EMBED_DIM);
var output = [];
for (var i = 0; i < x.length; i++) {
// 当前位置和前文做点积(因果 Mask:j <= i)
var scores = [];
for (var j = 0; j <= i; j++) scores.push(dot(Q[i], K[j]) * scale);
var attn = softmax(scores);
// 加权求和 Value
var row = new Array(EMBED_DIM).fill(0);
for (var j = 0; j <= i; j++) {
for (var d = 0; d < EMBED_DIM; d++) row[d] += attn[j] * V[j][d];
}
output.push(row);
}
return matMul(output, Wo);
}
// Feed Forward:对每个位置做升维 -> ReLU -> 降维
function feedForward(x) {
var hidden = matMul(x, W1);
// ReLU 激活
for (var i = 0; i < hidden.length; i++)
for (var j = 0; j < hidden[i].length; j++)
hidden[i][j] = hidden[i][j] > 0 ? hidden[i][j] : 0;
return matMul(hidden, W2);
}
// 一层 Decoder Block:Self-Attention -> Add & Norm -> FFN -> Add & Norm
// 输入 x:seqLen × EMBED_DIM 矩阵(如 5×16,5 个 token,每个 16 维向量)
// 输出:同样是 seqLen × EMBED_DIM 矩阵,形状不变,但每个位置的向量已带上前文信息
function decoderBlock(x) {
// Self-Attention
// 输入:x (seqLen × EMBED_DIM)
// 输出:attnOut (seqLen × EMBED_DIM),每个位置融合了前文信息
var attnOut = selfAttention(x);
// 残差连接 + LayerNorm
// 把原始输入 x 和 attention 输出逐位置相加,再做归一化
// 输入:x[i] (EMBED_DIM 向量) + attnOut[i] (EMBED_DIM 向量)
// 输出:afterAttn (seqLen × EMBED_DIM),数值更稳定的融合结果
var afterAttn = [];
for (var i = 0; i < x.length; i++) afterAttn.push(addNorm(x[i], attnOut[i]));
// Feed Forward
// 输入:afterAttn (seqLen × EMBED_DIM)
// 中间:hidden (seqLen × D_FF),先升维到 64 维,过 ReLU
// 输出:ffnOut (seqLen × EMBED_DIM),再降维回 16 维,对每个位置做进一步加工
var ffnOut = feedForward(afterAttn);
// 残差连接 + LayerNorm
// 输入:afterAttn[i] (EMBED_DIM 向量) + ffnOut[i] (EMBED_DIM 向量)
// 输出:output (seqLen × EMBED_DIM),最终的 Decoder Block 输出
var output = [];
for (var i = 0; i < afterAttn.length; i++) output.push(addNorm(afterAttn[i], ffnOut[i]));
return output;
}decoderBlock 做的事情可以对照前面的文字:
Self-Attention(每个位置参考前文)
-> 残差连接 + LayerNorm
-> Feed Forward(进一步加工每个位置)
-> 残差连接 + LayerNorm
-> 输出形状不变,但每个位置的向量已带上上下文信息因果 Mask 体现在 selfAttention 的内层循环:for (var j = 0; j <= i; j++) —— 第 i 个位置只能看到第 0 到第 i 个位置,不会偷看未来。
采样:从 logits 到 token
LM Head 输出的是 logits(原始分数),还不是 token。采样策略决定最终选哪个 token。这里实现 05-token_sample 里讲的完整流程:
// 采样策略:logits -> temperature -> top-k -> top-p -> multinomial -> token id
// 输入:logits(VOCAB_SIZE 个原始分数)
// 输出:一个 token id
// temperature:控制随机程度,低则稳定,高则发散
// topKVal:只保留概率最高的 k 个候选
// topPVal:在 top-k 结果上,再保留累计概率达到 p 的候选
function sampleToken(logits, temperature, topKVal, topPVal) {
// 1. temperature:除以温度,调整分数分布的锐利程度
var scaled = [];
for (var i = 0; i < logits.length; i++) scaled.push(logits[i] / temperature);
// 2. top-k:只保留前 k 个,其余设为 -Infinity
var sorted = scaled.slice().sort(function (a, b) { return b - a; });
var threshold = sorted[topKVal - 1];
var filtered = [];
for (var i = 0; i < scaled.length; i++) {
filtered.push(scaled[i] >= threshold ? scaled[i] : -Infinity);
}
// 3. top-p:保留累计概率达到 p 的一组候选,其余设为 -Infinity
var probs = softmax(filtered);
var indexed = [];
for (var i = 0; i < probs.length; i++) indexed.push({ id: i, prob: probs[i] });
indexed.sort(function (a, b) { return b.prob - a.prob; });
var cumulative = 0;
var keep = {};
for (var i = 0; i < indexed.length; i++) {
cumulative += indexed[i].prob;
keep[indexed[i].id] = true;
if (cumulative >= topPVal) break;
}
var final = [];
for (var i = 0; i < filtered.length; i++) {
final.push(keep[i] ? filtered[i] : -Infinity);
}
// 4. softmax 得到最终概率,multinomial 按概率随机抽一个
var finalProbs = softmax(final);
var r = Math.random();
var cumSum = 0;
for (var i = 0; i < finalProbs.length; i++) {
cumSum += finalProbs[i];
if (r < cumSum) return i;
}
return finalProbs.length - 1;
}组装推理循环
把上面的组件串起来,就得到一个完整的推理过程:输入文本,循环生成,输出结果:
// 单步推理:给定 token id 序列,预测下一个 token id
function predictNextToken(tokenIds, temperature, topKVal, topPVal) {
// 1. Embedding 查表
var x = [];
for (var i = 0; i < tokenIds.length; i++) x.push(embedding[tokenIds[i]].slice());
// 2. 加位置编码
var pe = positionalEncoding(x.length);
for (var i = 0; i < x.length; i++)
for (var j = 0; j < EMBED_DIM; j++) x[i][j] += pe[i][j];
// 3. Decoder Block
x = decoderBlock(x);
// 4. 取最后位置,过 LM Head 得到 logits
// 输入:最后位置的向量 (EMBED_DIM)
// 输出:logits (VOCAB_SIZE),词表里每个 token 的原始分数
var last = x[x.length - 1];
var logits = [];
for (var j = 0; j < VOCAB_SIZE; j++) {
var s = 0;
for (var i = 0; i < EMBED_DIM; i++) s += last[i] * Wlm[i][j];
logits.push(s);
}
// 5. 采样:logits -> token id
return sampleToken(logits, temperature, topKVal, topPVal);
}
// 完整推理:输入文本,循环生成,直到遇到 <eos> 或达到最大长度
function generate(prompt, maxLen, temperature, topKVal, topPVal) {
var ids = tokenize(prompt);
for (var step = 0; step < maxLen; step++) {
var nextId = predictNextToken(ids, temperature, topKVal, topPVal);
ids.push(nextId);
if (nextId === EOS_ID) break;
}
return detokenize(ids);
}
// 运行!
// temperature=0.8:略有随机性
// top_k=10:只看前 10 个候选
// top_p=0.9:累计概率达到 90% 就够
console.log("输入: hello");
console.log("输出:", generate("hello", 20, 0.8, 10, 0.9));sampleToken 的采样过程可以对照 采样一个 token 里的描述:
logits(原始分数)
-> temperature 调整随机程度
-> top-k 过滤低排名候选
-> top-p 保留累计概率足够高的候选
-> softmax 得到概率分布
-> multinomial 按概率抽出一个 token每次运行可能输出不同的结果,因为 multinomial 采样带有随机性。如果想得到确定的结果,可以把 temperature 设得很低(如 0.01),效果接近 argmax。
因为权重是用伪随机数生成的(不是真正训练过的),所以输出的内容没有实际语义。但整条推理链路是完整的:
文本 -> tokenize -> embedding + 位置编码 -> Decoder Block -> LM Head -> 采样 -> 拼回上下文 -> 循环对着代码回顾整章
读这段代码时,可以按本章主线对应:
tokenize() -> 切成 token
embedding[] -> Token Embedding 查表
positionalEncoding() -> 位置编码
decoderBlock() -> Decoder Block(Self-Attention + Add & Norm + FFN + Add & Norm)
selfAttention() -> 每个位置参考前文(因果 Mask 在 j <= i 的循环里)
addNorm() -> 残差连接 + LayerNorm
feedForward() -> 进一步加工每个位置
Wlm + sampleToken() -> LM Head 映射到词表,采样选出 token
generate() -> 组装推理循环,直到结束这就是一个最小的、可运行的 Decoder-Only Transformer 推理实现。真正的模型(比如 MiniMind、GPT)在结构上和这段代码完全一致,区别只是词表更大、维度更高、Decoder Block 层数更多、权重是真正训练出来的。