预训练回顾
这一章我们从数据准备到训练循环到工程细节,完整走了一遍预训练流程。下面把关键内容串起来回顾一下。
全流程回顾
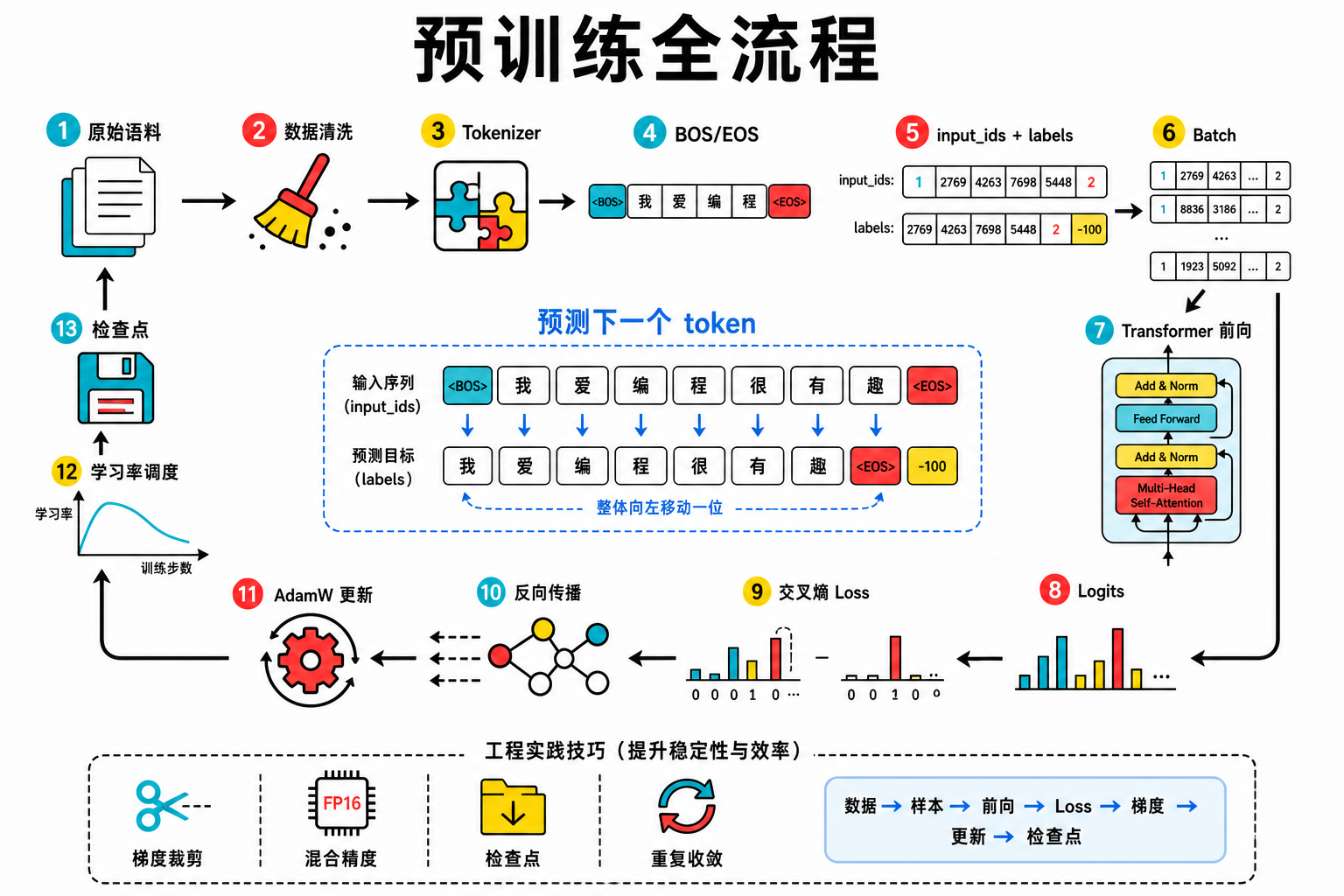
预训练的完整链路可以用这条主线串起来:
原始语料(网页、书籍、百科……)
→ 数据清洗(去重、过滤低质量内容)
→ 分词(tokenizer 切成 token)
→ 加 BOS/EOS 特殊标记
→ 截断/填充,构建训练样本(input_ids + labels)
→ 打包成 batch
→ 前向传播(Embedding → Decoder Blocks → LM Head → logits)
→ 交叉熵损失(logits vs labels)
→ 反向传播(计算梯度)
→ AdamW + 学习率调度 + 梯度裁剪
→ 参数更新
→ 保存检查点
→ 重复直到收敛按顺序回顾每个环节做了什么:
数据清洗:从原始语料中去掉重复文本、过滤太短或质量太差的内容。这一步决定了模型能学到的语言质量的天花板——垃圾进,垃圾出。实际工程中,数据清洗可能占到整个预训练项目一半以上的工作量。
分词 + 加特殊标记:用 tokenizer(比如 BPE 算法)把清洗后的文本切成 token 序列。每个 token 对应词表里的一个编号(token id)。然后在开头加 BOS 标记(告诉模型"一段新文本开始了"),结尾加 EOS 标记(告诉模型"这段文本结束了")。
截断/填充,构建训练样本:每个样本截断或填充到固定长度(比如 MiniMind 用的 340 个 token)。填充用 0 补齐,方便打包成整齐的矩阵。然后构造 labels——内容和 input_ids 一样,但向左偏移一位,意思是每个位置都在学习预测下一个 token。padding 位置的 labels 设为 -100,损失计算时会自动忽略,不会被无意义的填充内容干扰训练。
前向传播:一个 batch 的 input_ids 进入模型,经过 Token Embedding 查表变成向量、加上位置编码、经过多层 Decoder Block 逐步融合上下文信息、最后通过 LM Head 输出 logits。每个位置都给出了词表里所有 token 的原始分数——分数越高,模型越认为那个 token 是正确答案。
交叉熵损失:把 logits 和 labels 对比,算出模型预测得有多差。每个位置都算一个损失,最后取平均。训练初期 loss 大约 8-9(接近随机猜的损失),随着训练推进逐步降到 3 左右甚至更低。
反向传播 + 参数更新:从损失出发,沿着计算图反向算出每个参数的梯度(参数该往哪调、调多少)。然后 AdamW 优化器根据梯度更新参数——学习率在训练过程中按余弦曲线动态变化,梯度会被裁剪防止"走太远"。
保存检查点:定期把模型参数、优化器状态、训练进度保存到硬盘。万一训练中断,可以从最近的检查点恢复,不用从头来。
整个训练过程就是把这个循环跑成千上万次。每一步,模型的参数都往"预测更准"的方向挪一小步。几万步下来,一个随机输出乱码的模型就慢慢学会了语言的规律。
一个样本的完整旅程
用一个具体例子把上面各个环节串起来。假设训练数据中有这样一段文本:
今天天气很好,适合出门散步。它的完整旅程是这样的:
1. 原始文本:
今天天气很好,适合出门散步。
2. 分词(BPE):
[今天, 天气, 很好, ,, 适合, 出门, 散步, 。]
3. 加特殊标记,转成 token id:
[BOS, 128, 923, 512, 17, 2048, 9, 64, 88, EOS]
↓ 补齐到固定长度(假设为 10),刚好不需要填充
4. 构造 input_ids 和 labels:
input_ids: [BOS, 128, 923, 512, 17, 2048, 9, 64, 88, EOS]
labels: [128, 923, 512, 17, 2048, 9, 64, 88, EOS, -100]
↑ labels 比 input_ids 左移了一位,每个位置都在预测下一个 token
5. 前向传播:
input_ids → Embedding → 位置编码 → 8 层 Decoder Block → LM Head → logits
logits 形状:[10, 6400](10 个位置,每个位置 6400 个候选 token 的分数)
6. 计算损失:
logits 和 labels 对比,10 个位置各算一个交叉熵,取平均
7. 反向传播 → 梯度累积 → 梯度裁剪 → 参数更新
8. 下一个样本,重复上述过程这就是一个训练样本从原始文本到参数更新的完整旅程。实际训练中,每个 step 不是只处理一个样本,而是一个 batch(32 个样本同时走这条链路)。
关键要点
回顾这一章,核心知识点可以压缩成四个:
预训练目标:自回归语言建模——给定前面的 token,预测下一个 token。推理时我们只关心最后一个位置的预测,但训练时每个位置都在同时学习。模型通过海量文本反复练习这个任务,逐步掌握语言的统计规律——什么样的词后面通常接什么词,什么样的句子结构是通顺的,什么样的知识是事实。
数据:从原始文本到训练样本的流水线是:文本 → 分词 → 加特殊标记 → 截断/填充 → 构造 labels。其中 labels 的构造最关键——向左偏移一位,padding 位置用 -100 忽略。这保证了模型在每个位置都看到正确的前文,学习预测正确的下一个 token。MiniMind 的数据格式很简单:JSONL 文件,每行一个 {"text": "..."},大量的纯文本,没有标签和分类。
训练循环:核心是四步循环:前向传播 → 交叉熵损失 → 反向传播 → 参数更新。前向传播让模型做出预测,交叉熵衡量预测有多差,反向传播算出参数该怎么调,参数更新执行调整。然后拿下一个 batch,重复。MiniMind 的 batch size 是 32,每个 step 处理 32 个训练样本。
工程细节:让训练跑稳跑快的五个技巧——warmup + cosine decay(学习率先慢后快再慢,前期稳定方向,后期精细调整,从 lr 降到 lr × 0.1)、梯度累积(用多个小 batch 模拟大 batch,用时间换显存,MiniMind 累积 8 步,等效 batch size = 256)、梯度裁剪(限制梯度总长度,阈值 1.0,防止某一步走太远导致训练崩溃)、混合精度(前向和反向用 16 位,参数更新用 32 位,显存减半速度翻倍,几乎不影响模型质量)、检查点保存(每 1000 步存档一次,防止意外中断后从头训练)。
这五个技巧可以用一个跑步的类比来理解:学习率调度是配速策略——开始稳住节奏,中段发力,最后冲刺精调;梯度累积是分段跑——不能一口气跑完就分几段,效果差不多;梯度裁剪是限速——不管下坡有多陡,步子不能迈太大;混合精度是轻装上阵——不是所有装备都要带最重的;检查点是补给站——定期补给,出了状况能回退。
用代码跑通训练循环:一个最小的训练循环
上一章(推理过程回顾)我们用纯 JavaScript 跑通了一个最小 Transformer 的推理链路。那段代码用随机初始化的权重做推理,输出的是乱码——因为模型还没有经过训练。
现在,我们在那段推理代码的基础上,加上训练循环,让模型从随机参数开始,通过训练学会预测下一个字符。
完整可运行版本(推理 + 训练合并在一个文件中)见项目根目录的 tinymind.js,运行 node tinymind.js 即可看到 loss 从 3.x 降到 1.x,以及训练前后的推理结果变化。
复用推理代码
以下代码直接复用自推理过程回顾,不再重复解释。如果你还没跑过那段代码,需要先把词表、矩阵运算、模型结构、权重初始化的代码复制过来:
复用的部分:
chars, VOCAB_SIZE, EOS_ID, tokenize(), detokenize()
EMBED_DIM, D_FF, createRng(), randomMatrix()
matMul(), dot(), softmax(), layerNorm(), addNorm()
positionalEncoding(), selfAttention(), feedForward(), decoderBlock()
embedding, Wq, Wk, Wv, Wo, W1, W2, Wlm第一步:训练模式的前向传播
推理时我们只取最后一个位置的 logits,训练时需要所有位置的 logits——因为每个位置都在学习预测下一个 token:
// 训练模式的前向传播:返回所有位置的 logits
// 输入:tokenIds(一个 token id 数组)
// 输出:logits 矩阵 [seqLen × VOCAB_SIZE]
function forwardTrain(tokenIds) {
// Embedding 查表 + 位置编码 + Decoder Block(和推理一样)
var x = [];
for (var i = 0; i < tokenIds.length; i++) x.push(embedding[tokenIds[i]].slice());
var pe = positionalEncoding(x.length);
for (var i = 0; i < x.length; i++)
for (var j = 0; j < EMBED_DIM; j++) x[i][j] += pe[i][j];
x = decoderBlock(x);
// 和推理的区别:用 LM Head 对所有位置算 logits,不只是最后一个
return matMul(x, Wlm);
}第二步:交叉熵损失
上一篇讲过,交叉熵 = -log(正确 token 的概率)。这里对每个位置都算一个,然后取平均。注意偏移一位:位置 i 的 logits 预测的是 token i+1:
// 交叉熵损失:logits 的前 L-1 个位置 vs labels 的后 L-1 个位置
function crossEntropyLoss(logits, tokenIds) {
var totalLoss = 0;
var count = 0;
for (var i = 0; i < logits.length - 1; i++) {
var probs = softmax(logits[i]);
var target = tokenIds[i + 1]; // 偏移一位:位置 i 预测 token i+1
var p = Math.max(probs[target], 1e-10); // 防止 log(0)
totalLoss += -Math.log(p);
count++;
}
return totalLoss / count;
}
// 计算当前 loss 的辅助函数
function computeLoss(tokenIds) {
var logits = forwardTrain(tokenIds);
return crossEntropyLoss(logits, tokenIds);
}第三步:数值梯度
JavaScript 没有自动微分(PyTorch 的 backward()),所以我们用最朴素的方法计算梯度:对每个参数加一个小量 epsilon,看损失变了多少。梯度 = (loss_plus - loss_minus) / (2 × epsilon)。
这个方法虽然慢,但非常直观——它直接回答了"参数动一点点,损失会怎么变"这个问题:
// 数值梯度:对矩阵的每个元素逐一计算梯度
function numericalGradient(weightMatrix, lossFn, eps) {
var grad = [];
for (var i = 0; i < weightMatrix.length; i++) {
var gradRow = [];
for (var j = 0; j < weightMatrix[i].length; j++) {
var orig = weightMatrix[i][j];
// 加 eps,算 loss
weightMatrix[i][j] = orig + eps;
var lossPlus = lossFn();
// 减 eps,算 loss
weightMatrix[i][j] = orig - eps;
var lossMinus = lossFn();
// 恢复原值
weightMatrix[i][j] = orig;
gradRow.push((lossPlus - lossMinus) / (2 * eps));
}
grad.push(gradRow);
}
return grad;
}第四步:梯度裁剪
限制所有梯度的 L2 范数,防止某一步走太远:
// 梯度裁剪:计算所有梯度的 L2 范数,超过阈值就等比缩小
function clipGradients(allGrads, maxNorm) {
var totalNormSq = 0;
for (var g = 0; g < allGrads.length; g++)
for (var i = 0; i < allGrads[g].length; i++)
for (var j = 0; j < allGrads[g][i].length; j++)
totalNormSq += allGrads[g][i][j] * allGrads[g][i][j];
var totalNorm = Math.sqrt(totalNormSq);
if (totalNorm > maxNorm) {
var scale = maxNorm / totalNorm;
for (var g = 0; g < allGrads.length; g++)
for (var i = 0; i < allGrads[g].length; i++)
for (var j = 0; j < allGrads[g][i].length; j++)
allGrads[g][i][j] *= scale;
}
return totalNorm;
}第五步:简单 AdamW 优化器
为每个参数维护一阶矩(m)和二阶矩(v)的滑动平均,实现自适应学习率 + 权重衰减:
var adamState = {};
// 创建一个和矩阵同形状的全零矩阵
function zerosLike(m) {
var result = [];
for (var i = 0; i < m.length; i++) {
var row = [];
for (var j = 0; j < m[i].length; j++) row.push(0);
result.push(row);
}
return result;
}
// AdamW 参数更新
function adamWUpdate(name, weights, grads, lr, beta1, beta2, eps, weightDecay, t) {
if (!adamState[name]) {
adamState[name] = { m: zerosLike(weights), v: zerosLike(weights) };
}
var s = adamState[name];
for (var i = 0; i < weights.length; i++) {
for (var j = 0; j < weights[i].length; j++) {
// 更新一阶矩和二阶矩
s.m[i][j] = beta1 * s.m[i][j] + (1 - beta1) * grads[i][j];
s.v[i][j] = beta2 * s.v[i][j] + (1 - beta2) * grads[i][j] * grads[i][j];
// 偏差校正
var mHat = s.m[i][j] / (1 - Math.pow(beta1, t));
var vHat = s.v[i][j] / (1 - Math.pow(beta2, t));
// 参数更新 = 自适应学习率 + 权重衰减
weights[i][j] -= lr * (mHat / (Math.sqrt(vHat) + eps) + weightDecay * weights[i][j]);
}
}
}第六步:梯度累积
攒 N 个 batch 的梯度再更新参数,模拟更大的 batch size:
// 把 newGrad 累加到 accGrad 上
function addGradients(accGrad, newGrad) {
for (var i = 0; i < accGrad.length; i++)
for (var j = 0; j < accGrad[i].length; j++)
accGrad[i][j] += newGrad[i][j];
}组装训练循环
把上面的组件串起来,就得到一个完整的训练循环。训练数据是几段英文短句,每个 step 随机取一段来训练:
// 所有需要训练的权重
var allWeights = [embedding, Wq, Wk, Wv, Wo, W1, W2, Wlm];
var weightNames = ["embedding", "Wq", "Wk", "Wv", "Wo", "W1", "W2", "Wlm"];
// 训练超参数
var LR = 0.01;
var ACCUMULATION_STEPS = 3; // 梯度累积 3 步
var GRAD_CLIP = 1.0; // 梯度裁剪阈值
var EPS = 0.001; // 数值梯度的 epsilon
// 训练数据:多段短文本
var trainData = [
"hello world",
"this is a test",
"training is fun",
"hello this is fun",
"world of testing",
"a test of training"
];
// 预先 tokenize
var trainIds = [];
for (var d = 0; d < trainData.length; d++) {
trainIds.push(tokenize(trainData[d]));
}
// 训练循环
var t = 0; // AdamW 的步数计数器
for (var step = 0; step < 30; step++) {
// 初始化累积梯度(全零)
var accGrads = [];
for (var w = 0; w < allWeights.length; w++) {
accGrads.push(zerosLike(allWeights[w]));
}
// 梯度累积:攒 ACCUMULATION_STEPS 个 batch
for (var acc = 0; acc < ACCUMULATION_STEPS; acc++) {
var idx = Math.floor(Math.random() * trainIds.length);
var ids = trainIds[idx];
var lossFn = function() { return computeLoss(ids); };
// 对每个权重矩阵计算数值梯度
for (var w = 0; w < allWeights.length; w++) {
var grad = numericalGradient(allWeights[w], lossFn, EPS);
// 除以累积步数(取平均)
for (var i = 0; i < grad.length; i++)
for (var j = 0; j < grad[i].length; j++)
grad[i][j] /= ACCUMULATION_STEPS;
addGradients(accGrads[w], grad);
}
}
// 梯度裁剪
clipGradients(accGrads, GRAD_CLIP);
// AdamW 参数更新
t++;
for (var w = 0; w < allWeights.length; w++) {
adamWUpdate(weightNames[w], allWeights[w], accGrads[w],
LR, 0.9, 0.999, 1e-8, 0.01, t);
}
// 每 3 步打印一次 loss
if (step % 3 === 0) {
var totalLoss = 0;
for (var d = 0; d < trainIds.length; d++) totalLoss += computeLoss(trainIds[d]);
console.log("step " + step + ", avg loss: " + (totalLoss / trainIds.length).toFixed(4));
}
}运行结果大致是这样的:
step 0, avg loss: 3.2871
step 3, avg loss: 2.8846
step 6, avg loss: 2.6341
step 9, avg loss: 2.4141
step 12, avg loss: 2.1609
step 15, avg loss: 1.9328
step 18, avg loss: 1.7309
step 21, avg loss: 1.5520
step 24, avg loss: 1.4058
step 27, avg loss: 1.2589loss 在持续下降——从 3.29 降到 1.26。这就是训练在做的事情:每一步都在微调参数,让模型的预测越来越准。
训练后推理:看看模型学到了什么
训练完后,用推理章节的 generate() 函数(去掉训练代码,只保留推理部分),看看模型从 "hello" 开始能生成什么:
// 训练前(随机权重)生成:hellois of thinfvpunnunis
// 训练后生成: hello folld uningsynxnld训练后的输出虽然还不是有意义的句子(毕竟模型太小、训练数据太少、训练步数不够),但能看到一些变化——模型开始模仿训练数据中出现的字符组合模式("hello"、"this is"、"training" 等片段的字符接续)。
对着代码回顾整章
读这段代码时,可以按本篇的训练循环主线对应:
forwardTrain() → 前向传播(所有位置的 logits)
crossEntropyLoss() → 交叉熵损失(-log(正确 token 的概率))
numericalGradient() → 反向传播(数值方法计算梯度)
clipGradients() → 梯度裁剪(限制步长)
adamWUpdate() → 参数更新(AdamW:自适应学习率 + 权重衰减)
addGradients() → 梯度累积(攒几步再更新)和 MiniMind 的训练循环(PyTorch + 自动微分 + GPU 加速)相比,这段 JS 代码在结构上完全一致——前向 → 损失 → 梯度 → 更新,只是实现方式不同。PyTorch 用自动微分算梯度(快且精确),这里用数值方法(慢但直观);PyTorch 在 GPU 上并行计算,这里在 CPU 上串行计算。原理一样,工程效率天差地别。
如何用 MiniMind 跑预训练
如果你想自己动手跑一遍,MiniMind 提供了一键启动的训练脚本。前提条件很简单:
- 一台有 NVIDIA GPU 的机器(显存至少 8GB)
- 配好 Python 环境,安装 PyTorch
- 准备好预训练数据文件(JSONL 格式,每行一个
{"text": "..."})
然后在项目根目录下运行:
python trainer/train_pretrain.py \
--epochs 2 \
--batch_size 32 \
--learning_rate 5e-4 \
--accumulation_steps 8 \
--grad_clip 1.0 \
--hidden_size 768 \
--num_hidden_layers 8 \
--max_seq_len 340 \
--data_path ../dataset/pretrain_t2t_mini.jsonl每个参数的含义:
epochs:训练轮数。2 表示把所有训练数据看 2 遍。轮数越多模型学得越充分,但也可能过拟合。batch_size:每个 step 处理的样本数。32 个样本一起算前向和反向。受 GPU 显存限制,不能设太大。learning_rate:初始学习率。5e-4(即 0.0005)。训练过程中会按余弦曲线自动衰减,不需要手动调整。accumulation_steps:梯度累积步数。8 表示攒 8 个 batch 的梯度才更新一次参数。等效 batch size = 32 × 8 = 256,用更多时间换取更大的有效 batch。grad_clip:梯度裁剪阈值。1.0 表示梯度 L2 范数超过 1.0 就等比缩小。防止训练中偶尔出现的梯度爆炸。hidden_size:隐藏层维度。768 对应一个约 64M 参数的小模型。这个值越大,模型容量越大,但需要的显存和计算量也越多。num_hidden_layers:Transformer 的 Decoder Block 层数。8 层。层数越多,模型越"深",能学到越复杂的语言模式。max_seq_len:训练样本的最大长度。340 个 token。超过的文本会被截断,不够的用 0 填充。data_path:预训练数据文件的路径。指向一个 JSONL 格式的文件。
在单张 GPU 上,这个配置跑几个小时就能完成训练。训练过程中会打印日志,显示当前的 loss、学习率、预计剩余时间等信息。正常情况下 loss 应该从 8-9 持续下降到 3 左右。如果 loss 不降反升,可能是学习率太大或者数据有问题。
训练完成后,模型权重会保存到 out/ 目录下,可以直接用来做推理——拿我们在推理章节学到的流程,把训练好的模型加载进来,给它一段输入,它就能续写文本了。
预训练之后是什么
经过预训练,模型学会了"语言的规律"——它能续写文本,给它一段开头,它能接下去写。但它还不太会"对话"——你问它一个问题,它可能接着你的话往下编,而不是给出一个有条理的回答。
打个比方:预训练让模型成了一个博览群书但不会聊天的人。它读过无数文章,积累了庞大的知识储备和语言能力,但从来没练过"一问一答"这种对话格式。你问它"中国的首都是哪里",它可能回答"北京",但也可能续写成"中国的首都是哪里?这个问题很多人问过",因为它不知道什么是"回答问题",它只知道"接着往下写"。
下一步是 SFT 微调(Supervised Fine-Tuning)——用精心准备的对话和指令数据继续训练模型,教它按"用户问、助手答"的格式来组织输出。
微调的训练方式和预训练本质上是一样的:同样是预测下一个 token,同样是前向 → 损失 → 反向 → 更新的四步循环。区别在于数据——微调用的是人工准备的问答对和指令响应数据,而不是海量纯文本。数据从"什么都读"变成了"专门练对话"。
预训练决定了模型的知识储备和语言能力的天花板,微调决定了模型能不能把这些能力以对话的方式释放出来。两者缺一不可——没有预训练,模型连话都说不通;没有微调,模型不会按你期望的方式回答。
进阶方向
如果你想进一步了解预训练相关的技术,以下几个方向值得关注:
分布式训练:上面演示的是单 GPU 训练,但真正的预训练需要多 GPU 甚至多机器协同。最基本的方式是数据并行——把一个大 batch 拆到多张 GPU 上,每张卡独立算一部分样本的梯度,然后汇总起来统一更新参数。更大规模的训练还会用到张量并行(把一个矩阵乘法拆到多张卡上)和流水线并行(模型的不同层放在不同卡上,像流水线一样接力处理)。这些技术让训练几十亿甚至几百亿参数的模型成为可能。MiniMind 的代码已经支持单机多卡的数据并行训练。
MoE 架构:MiniMind 支持的另一种模型结构。MoE(Mixture of Experts,混合专家)的思路是:模型的 Feed Forward 层不是一组参数,而是有很多组——每一组就是一个"专家"。每个 token 只激活其中少数几个专家来处理,而不是全部。这样一来,模型的总参数可以很多(知识容量大),但实际计算量不增加(每次只用到一小部分参数)。效果是:用同样的计算预算,得到一个知识更丰富的模型。后续章节会单独展开 MoE 的细节。
数据质量的影响:这一章我们主要关注了训练的"怎么做",但预训练数据的质量和多样性直接决定模型能力的天花板。数据清洗的严格程度、不同领域文本的配比(代码占多少、百科占多少、网页占多少)、去重策略的选择(精确去重还是模糊去重)——这些看似枯燥的数据工程决策,对最终模型效果的影响往往比调整模型结构更大。这也是为什么各大模型厂商在数据方面投入了大量精力,而且训练数据的具体构成通常是商业机密。