模型如何预测下一个 token
上一章讲到,tokenizer 会把完整 prompt 切成 token,并进一步转换成 token id。到了这一步,模型拿到的已经不是原始文本,而是一串数字:
为什么 / 天空 / 是 / 蓝色 / 的 / ?
[128, 923, 17, 2048, 9, 64, ...]本章要回答的问题是:模型如何根据这串 token id,预测下一个 token?
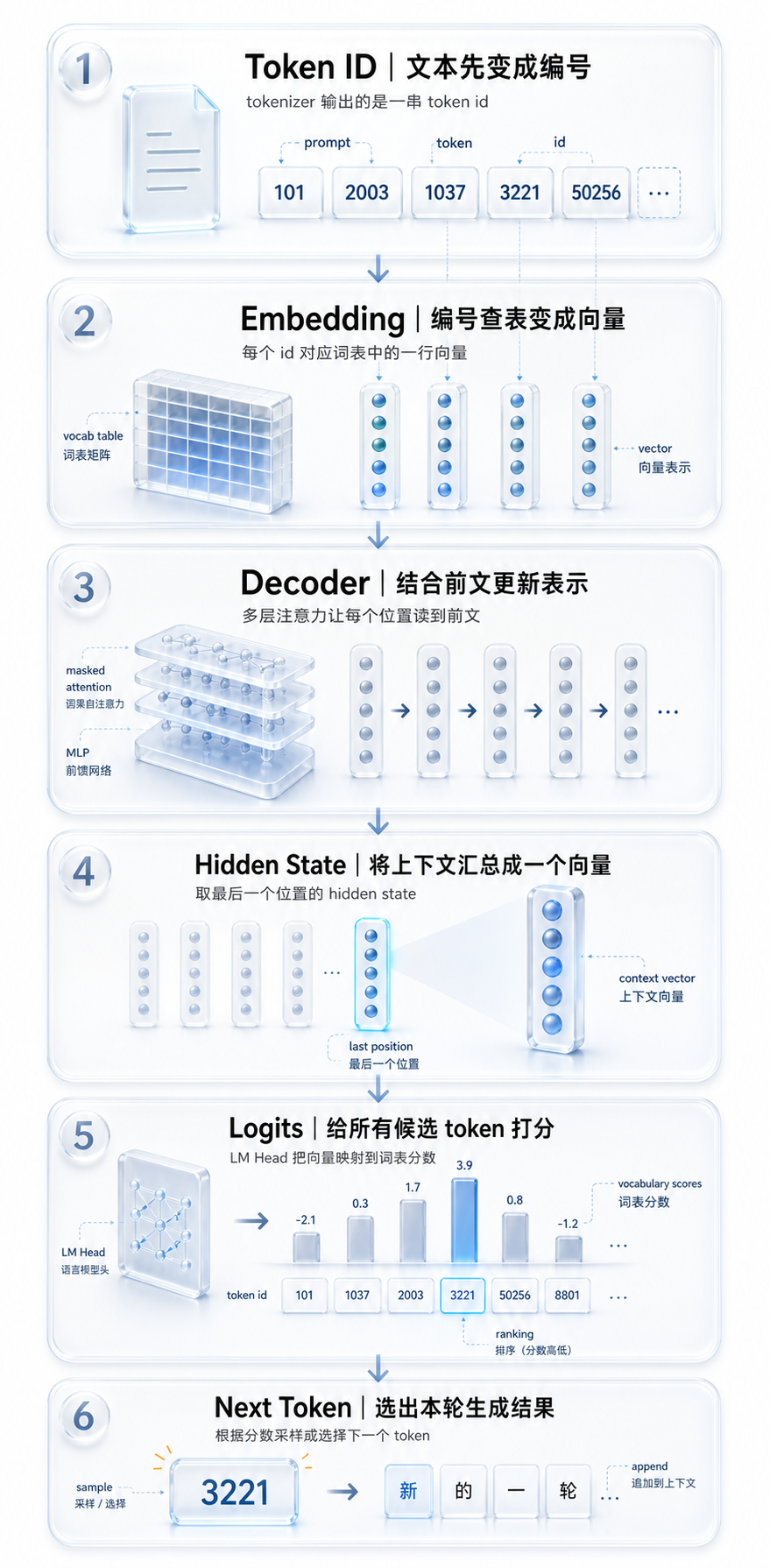
先看一张核心流程图:
token id 序列:每个 token 在词表中的编号
-> Token Embedding:把编号变成向量,这个向量是在训练中学出来的 token 表示
-> 多层 Decoder Block:结合前文,更新每个位置的上下文表示,让上下文信息不断向后累计
-> 最后一个位置的 hidden state:表示模型读完整段上下文后的当前状态,用来预测下一个 token
-> LM Head:把当前状态映射成整个词表上的分数,也就是 logits
-> 采样一个 token:根据 logits 得到的概率,选出一个 token 作为本轮生成结果这张图先不展开每个模块的数学细节,只先说明一件事:
token id 不是直接变成答案,
而是先变成向量,
再经过模型主体处理,
最后得到每个候选 token 的分数。token id 只是编号
token id 本身只是词表里的编号。
比如:
为什么 -> 128
天空 -> 923
是 -> 17这些数字不是自然语言里的“意思”,只是方便模型查表和计算的编号。128 本身不天然代表“为什么”,923 本身也不天然代表“天空”。
所以模型不能只拿这些编号直接推理。第一步通常是把 token id 转换成向量。
如果输入有 10 个 token,那么这里可以先把它看成一个长度为 10 的编号列表:
[128, 923, 17, 2048, 9, 64, 301, 88, 19, 2]它的形状可以记作:
10意思是:一共有 10 个 token id。
Token Embedding:把编号变成向量
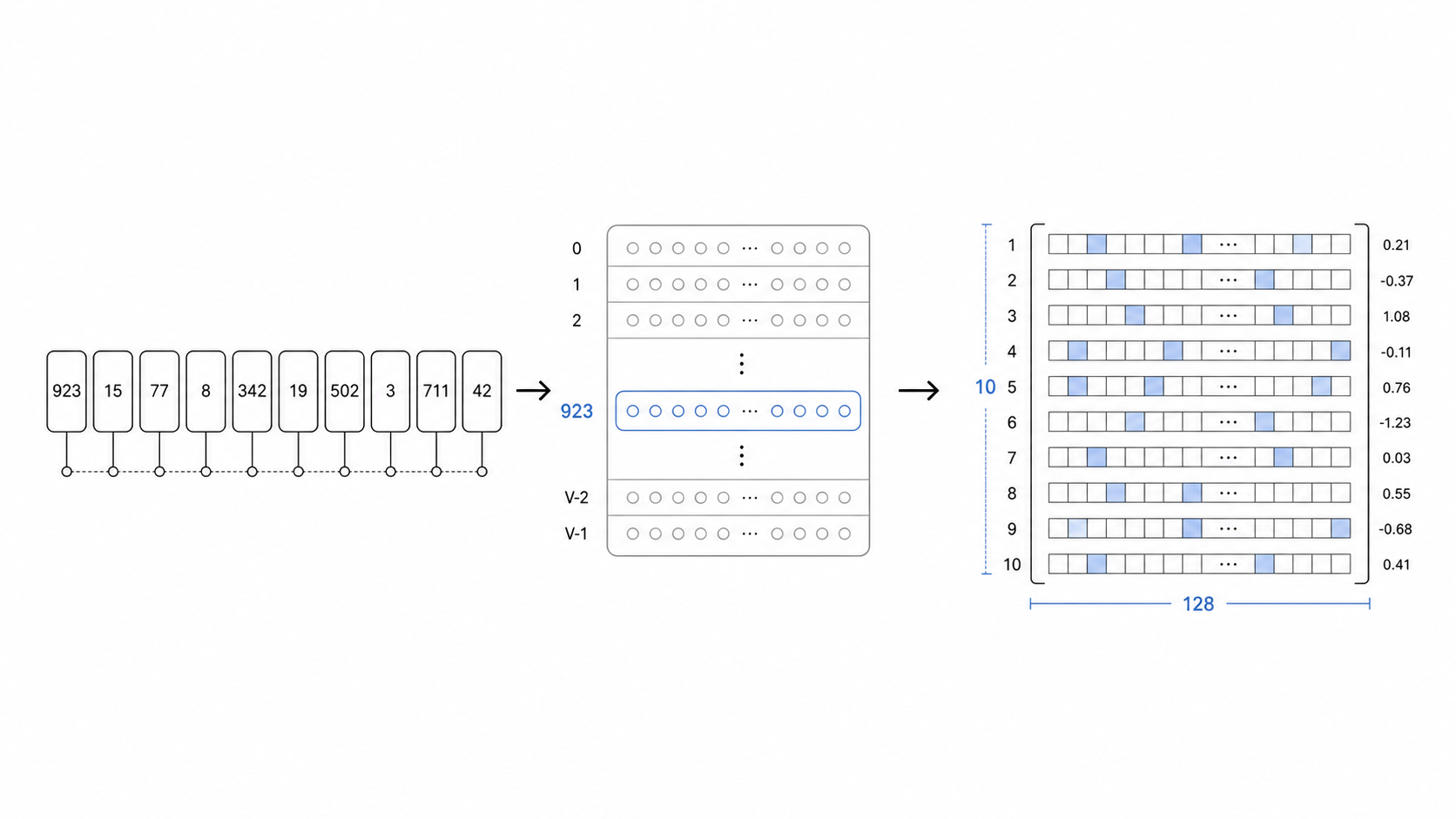
Token Embedding 可以理解成模型给每个 token 准备的一张“数字名片”。它的作用是把 token id 这个离散编号,转换成模型可以继续计算的向量。
当模型看到 token id 923 时,它会去 embedding 表里查出对应的向量:
923 -> [0.12, -0.38, 0.07, ...]这个向量才是模型真正拿来计算的东西。
如果输入是 10 个 token,并且每个 token embedding 是 128 维,那么经过 Token Embedding 后,会得到一个 10×128 的矩阵(10 行,128 列,每一行代表一个 token 的向量):
[
[0.11, 3.31, ..., 1.32], <- 第 1 个 token 的向量
[0.27, -0.42, ..., 0.08], <- 第 2 个 token 的向量
...
[3.41, 5.13, ..., -31.01] <- 第 10 个 token 的向量
]也就是说:
10 个 token id
-> 10 个 128 维向量
-> 形状:10×128Embedding 表不是人工写好的词义表,而是在训练过程中学出来的。训练刚开始时,这些向量通常只是随机数字;随着模型不断学习“前文后面应该接什么 token”,相关 token 的向量也会被一起调整。
如果两个 token 在训练中经常出现在相似语境里,它们的向量可能也会慢慢变得更接近。这样模型就能用向量来表达 token 之间的关系。
更详细的说明见延伸阅读:Embedding 是什么。
光是 Token Embedding 还不够:让模型知道顺序
只知道有哪些 token 还不够,模型还需要知道它们的顺序。
比如:
猫 追 狗
狗 追 猫这两句话包含的 token 很像,但意思完全不同。
因此,模型会给 token 向量加入位置信息,让它知道每个 token 出现在第几个位置。
最直观的位置编码做法来自经典 Transformer 论文《Attention Is All You Need》:先为每个位置准备一个固定的位置向量,然后把它加到 token embedding 上。
可以简单理解成:
最终输入向量 = token embedding + 位置向量如果 token embedding 已经是 10×128,位置向量也会准备成同样的形状:
token embedding: 10×128
position embedding: 10×128
sum: 10×128也就是说,加入位置信息不会改变矩阵大小,只是让每一行向量额外带上“我在第几个位置”的信息。
比如同一个 token “猫”,出现在不同位置时:
第 0 位的“猫”:猫的 token 向量 + 第 0 位的位置向量
第 3 位的“猫”:猫的 token 向量 + 第 3 位的位置向量这样模型看到的就不只是“这是猫”,还包含“这个猫出现在第几个位置”。MiniMind 这类 Decoder-only 模型也需要类似的位置信息,才能在处理上下文时区分先后顺序。
更详细的位置编码说明见延伸阅读:位置编码是什么。
Decoder Block:汇总上下文信息
加上位置信息后,这些 token 向量会进入多层 Decoder Block。
Decoder Block 的输入仍然是这个 10×128 矩阵:
输入:10×128
[
[第 1 个 token 的向量],
[第 2 个 token 的向量],
...
[第 10 个 token 的向量]
]这里先把 Decoder Block 理解成一个“阅读和加工上下文的模块”,它会理解整个句子,把整个句子的信息汇总到最后一个位置的向量上,也就是所谓的内部状态。
它会反复阅读前面的 token,
把“每个 token 是什么”和“它前面发生了什么”结合起来。比如模型看到:
用户:为什么天空是蓝色的?
助手:它不是只看最后的“助手:”,而是会参考前面的整个问题。经过 Decoder Block 处理后,最后位置的向量就会带上这样的信息:
用户问的是“为什么天空是蓝色的”
现在轮到助手回答
下一步应该开始解释原因这些信息不会以中文句子的形式存在,而是藏在一串数字向量里。这里先抓住主线:Decoder Block 会把一串 token 向量,加工成一串“读过上下文之后”的向量。
它的输出形状通常还是 10×128:
输出:10×128
[
[第 1 个位置读过上下文后的向量],
[第 2 个位置读过上下文后的向量],
...
[第 10 个位置读过上下文后的向量]
]也就是说:
Decoder Block:10×128 -> 10×128矩阵大小不变,但每一行的内容已经被更新了。
更详细的 Decoder Block 说明见:Decoder Block 是什么。
为什么看最后一个位置
在自回归生成里,模型每次要预测的是:
当前上下文后面的下一个 token因此,推理时通常最关心最后一个位置的向量。
如果当前上下文是:
用户:为什么天空是蓝色的?
助手:最后一个位置的向量可以理解成:
模型读完整段上下文后,对“下一步该说什么”形成的内部状态。如果 Decoder Block 输出是 10×128,那么取最后一个位置,就是取第 10 行:
10×128 矩阵
-> 取第 10 行
-> 1 个 128 维向量可以写成:
[3.41, 5.13, ..., -31.01] <- 128 维接下来,模型会把这个状态交给 LM Head。
LM Head:把状态映射到词表
LM Head 的作用,是根据上面这个状态给词表里的每个 token 打分。
前面 Decoder Block 已经得到一个“下一步该说什么”的状态。LM Head 会拿这个状态去问:
词表里的哪个 token 最适合接在后面?如果词表里有 6400 个 token,那么 LM Head 会输出 6400 个分数:
输入:1 个 128 维向量
输出:6400 个分数
token logit
---------------
这是 8.2
因为 7.9
天空 6.4
我们 4.1
蓝色 3.7
... ...这些分数就是 logits。它们表示模型认为每个 token 作为“下一个 token”的合适程度。
也就是说:
LM Head:128 -> 640关于 logits 的更详细解释,可以看延伸阅读:Logits 是什么。
有些模型会让 LM Head 和 token embedding 共享同一份权重。这里先不用深究细节,可以粗略理解成:词表里的每个 token 都有一个基础向量,LM Head 会拿当前状态去和这些 token 做匹配。
当前状态和“这是”这个 token 有多匹配?
当前状态和“因为”这个 token 有多匹配?
当前状态和“天空”这个 token 有多匹配?匹配程度越高,对应 token 的 logit 就越高。
需要注意的是,LM Head 不是直接忽略位置和上下文。位置和上下文已经在前面的 Decoder Block 里影响了“当前状态”,LM Head 只是基于这个状态给候选 token 打分。
本章到 logits 为止
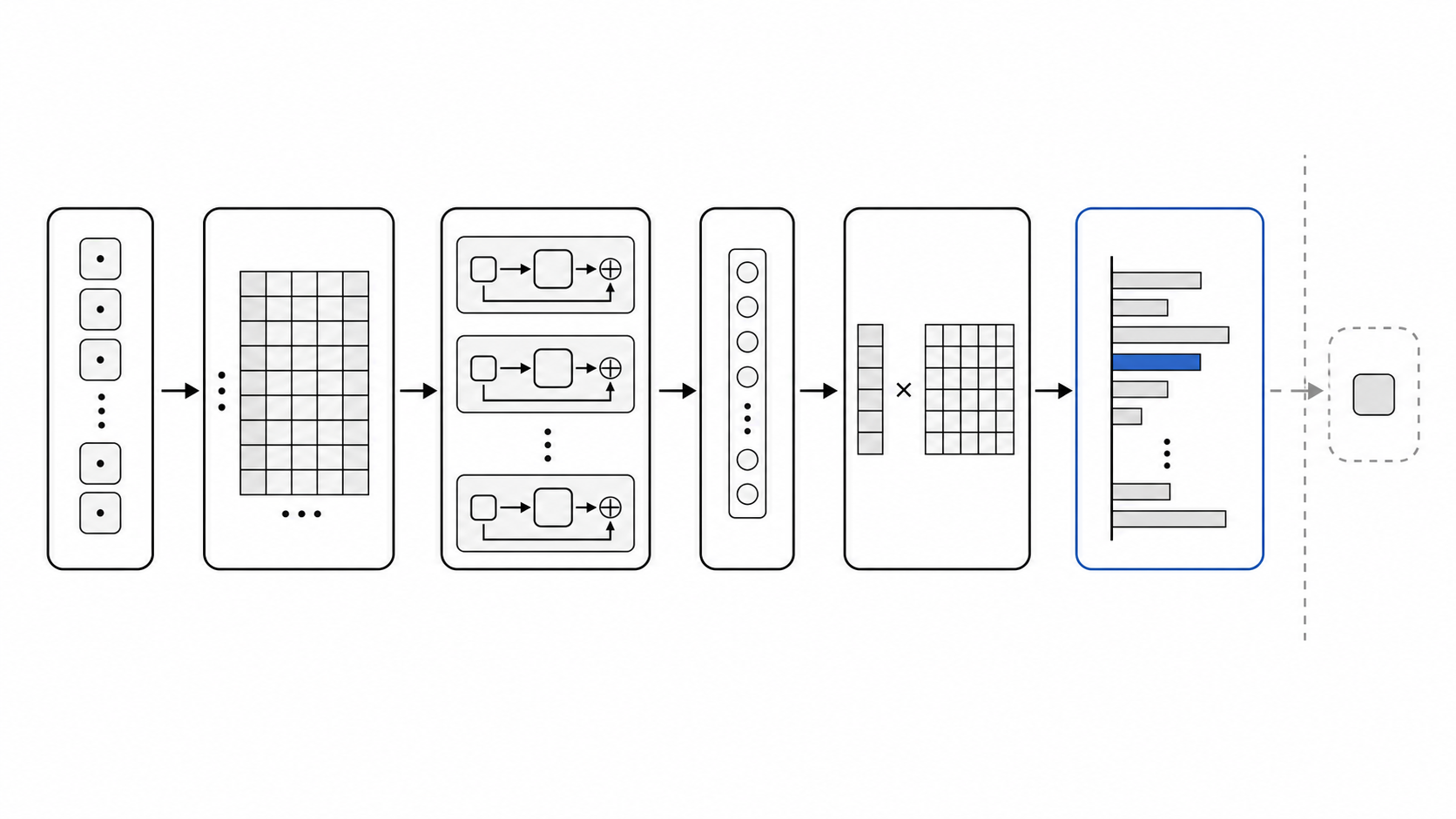
到这里,“模型预测下一个 token”这一步就完成了。
本章讲的是:
token id
-> embedding 向量
-> 加入位置信息
-> Decoder Block 结合上下文
-> 最后位置 hidden state
-> LM Head
-> logits但 logits 还不是最终输出。模型还需要根据 logits 转成概率,并结合 temperature、top-k、top-p、重复惩罚等策略,真正选出一个 token。
采样这一步可以理解成:
6400 个候选 token 分数
-> 选出 1 个 token id这就是下一章要讲的内容:采样一个 token。