神经网络是什么
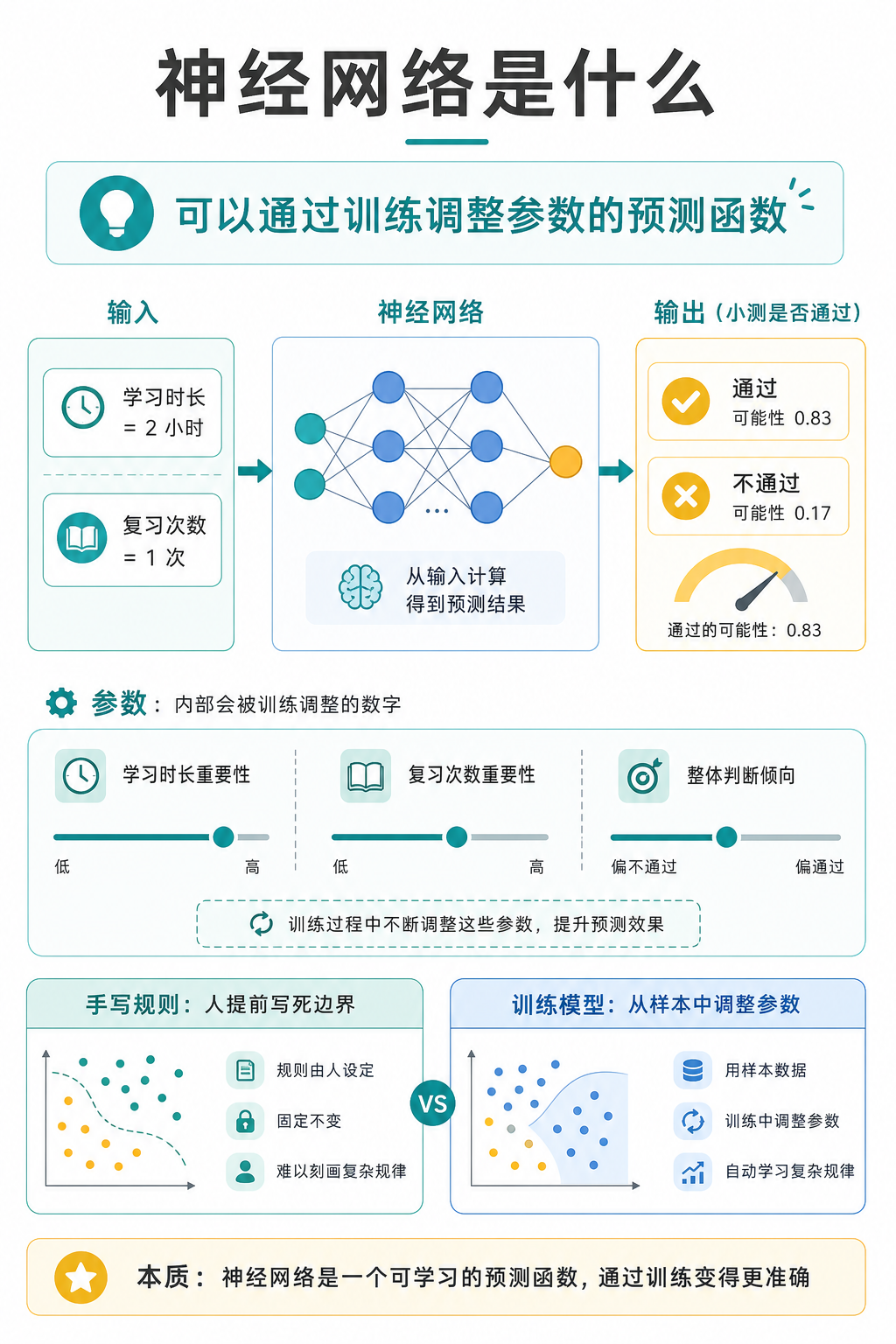
神经网络听起来像一个很复杂的东西,但在刚开始学习时,可以先把它理解成一种特殊的“预测函数”。
预测函数,就是给它一些输入,它会给出一个输出。比如我们想预测一次小测能不能通过,可以把“学习时长”和“复习次数”交给模型:
学习时长、复习次数 -> 模型 -> 是否通过小测这里的模型如果是神经网络,就意味着:它不是靠我们一条条写死规则来判断,而是可以通过训练,逐渐调整自己内部的一些数字,让预测结果越来越接近真实答案。
所以,本章先给出一个朴素定义:
神经网络是一种可以通过训练调整参数的预测函数。这个定义里有三个关键词:预测、训练、参数。预测是任务,训练是让它变好的过程,参数是内部会被训练调整的数字。
从一个预测问题开始
假设我们关心一个很小的学习场景:一个同学今天学习了 2 小时,复习了 1 次,我们想预测他明天的小测是否能通过。
可以把输入写成:
学习时长 = 2 小时
复习次数 = 1 次我们希望得到的输出是:
小测是否通过这就是一个预测问题。模型只需要根据给定的信息,给出一个可能的判断。
只看两个数字判断小测结果会有不确定性。模型做的是:在已有信息下,给出一个尽量合理的结果。
神经网络要学的,就是从类似这样的样本中找规律。一开始,它可能判断得很随意;训练之后,如果样本数量和质量合适,它就会逐渐学到:学习时长、复习次数和小测结果之间大概有什么关系。
模型不是手写规则
面对这个问题,我们也可以不用神经网络,直接手写规则。例如:
如果学习时长 >= 2 小时,并且复习次数 >= 1 次,就预测通过。
否则预测不通过。这条规则很直观,也容易解释。但它的问题是:规则由人提前写死,边界来自我们的假设。
如果后来发现很多同学学习 1.5 小时也能通过,这条规则就太严格了;如果发现只复习 1 次远远不够,这条规则又太宽松了。规则越写越多,边界也越来越难定。
训练模型的思路不同。我们不直接告诉模型完整规则,而是给它看许多“输入和真实结果”配对的样本。模型根据这些样本调整内部数字,让预测尽量接近训练数据里的真实结果。
人仍然要设计模型、准备数据、选择训练方式,但“具体怎样从输入走到预测”不再完全由手写规则决定。
参数:模型里会被训练调整的数字
那模型内部到底在调整什么?答案是:参数。
参数可以先理解成模型里面的一些数字。它们不会直接出现在输入里,也不是每次预测时临时填写的内容,更像模型内部的旋钮。
还是用小测预测的例子。模型可能需要决定:
学习时长的重要性有多大?
复习次数的重要性有多大?
整体上,预测通过应该更容易还是更谨慎?这些“重要性”和“倾向”最终都可以由一些数字来控制。训练开始前,这些数字通常还不合适,所以模型的预测可能很差。训练过程中,模型会比较自己的预测和真实答案,然后调整这些数字。
这里不需要知道参数具体怎么改,也不需要推公式。现在只要抓住一个直觉:
参数不是输入,而是模型内部会被训练调整的数字。输入是“学习时长 = 2 小时、复习次数 = 1 次”;参数是模型内部用来处理这些输入的数字。输入每个样本都可能不同,参数则是在训练中逐渐形成。
本章内容概览
这一章接下来会按“是什么、怎么预测、怎么评价、怎么训练”的顺序来讲神经网络。
第一步是认识神经网络是什么:它是一种根据输入预测输出的函数,内部有可以通过训练调整的参数。
第二步是理解神经网络如何完成预测。我们会先认识神经元、层、权重、偏置和激活函数,再看输入如何通过前向传播一步步变成输出。
第三步是理解如何评价预测好坏。损失函数会比较预测值和真实答案,把差距变成一个数字。
第四步是理解如何训练神经网络。训练会用损失函数衡量错误,再用反向传播和梯度下降更新参数。
可以把本章主线记成:
神经网络是什么
-> 神经网络如何完成预测
-> 如何衡量预测好坏
-> 如何训练神经网络各小节内容
01 神经元、层和前向传播:神经网络如何完成预测
01-basic-concepts.md 介绍神经网络内部最基础的部件。
这一节会解释一个神经元如何接收输入、使用权重和偏置进行计算,以及多个神经元如何组成一层。它还会说明为什么需要激活函数,并把这些部件串成一次前向传播:输入进入网络,中间层加工信息,输出层给出预测。
02 如何衡量一个神经网络的好坏:损失函数
02-loss-function.md 解释模型如何知道自己的预测好不好。
模型给出预测之后,需要和真实答案比较。损失函数的作用,就是把预测和真实答案之间的差距变成一个数字。这个数字越大,说明模型这次错得越严重;这个数字越小,说明预测更接近真实答案。
03 如何训练一个神经网络
03-training-neural-network.md 介绍神经网络如何从错误中调整参数。
这一节会把反向传播、梯度下降和训练循环放在一起讲。反向传播负责把错误信号传回参数,梯度下降负责按照方向更新参数,训练循环则让这个过程反复发生。
04 本章小结与练习
04-summary-and-practice.md 对整章内容做回顾,并用几个小练习检查理解。
这一节会重新梳理推理和训练的区别:前向传播属于推理路径,损失函数、反向传播、梯度下降和训练循环属于训练路径。它的目标是帮助读者确认自己已经抓住了本章主线。
本章主线
可以把本章内容压缩成一句话:
神经网络根据输入做预测;训练则通过比较预测和真实答案,反复调整参数,让预测逐步变好。接下来阅读每一节时,可以始终带着这个问题:
这一节讲的概念,属于“完成预测”,还是属于“改进预测”?只要能回答这个问题,本章的结构就已经理清楚了。
用代码理解:神经网络像一个带参数的函数
下面这段代码还不是完整训练,只是先把“输入、参数、预测”放在一起看。
function predict(studyHours, reviewTimes, parameters) {
var score =
studyHours * parameters["studyWeight"]
+ reviewTimes * parameters["reviewWeight"]
+ parameters["bias"];
if (score >= 0) {
return "通过";
}
return "未通过";
}
var parameters = {
"studyWeight": 0.8,
"reviewWeight": 1.2,
"bias": -2.0,
};
var result = predict(2, 1, parameters);
console.log(result);这段代码里,studyHours 和 reviewTimes 是输入;studyWeight、reviewWeight 和 bias 是参数。
如果只调用 predict(),参数不会自动变好。训练要做的事情,就是根据很多样本不断调整这些参数,让预测越来越接近真实答案。